CONSERVATOIRE
NATIONAL DES ARTS ET MÉTIERS
Centre Régional
Languedoc-Roussillon
Spécialité :
INFORMATIQUE
EXAMEN PROBATOIRE
Les techniques des moteurs de recherche
Soutenu le 10 Février 2003
par
Cédric
BOUTTES
JURY
Président : Jean-Yves RANCHIN
Membres
: Marc NANARD
Mathieu
LAFOURCADE
SOMMAIRE
INTRODUCTION………………………………………………………………………………1
I - LES DOCUMENTS DU
WEB ET SA STRUCTURE : IMPACT SUR LE TRAVAIL DES MOTEURS DE RECHERCHE……………………………………………………………………………………2
I-1.
Pages et documents ………………………………………………………………2
I-2
Eléments de structure des documents HTML ………………..……..……2
I-2-1 Les tags classiques…………………………………………………………… … 2
I-2-2 Les méta tags…………………………………………………………………… 3
I-3
Structure du Web et accessibilité des documents ………………….….4
I-3-1 Une structure
en nœud papillon…………………………………………………4
I-3-2 Le Web
invisible………………………………………………………………….5
II- ANNUAIRE ET MOTEURS DE
RECHERCHE : PRINCIPE GENERAL DE FONCTIONNEMENT………………………………………………....6
II-1. Les annuaires ……………………………………………………………………….6
II-2. Les moteurs de recherche ……………………………………………………..7
II-2-1
Définition………………………………………………………………………...7
II-2-2
Historique………………………………………………………………………..7
II-2-3 Le
fonctionnement d’un moteur de recherche………………………………...7
Ø
La collecte des données………………………………………………………7
Ø
L’indexation…………………………………………………………………..8
Ø
Recherche et présentation des pages………………………………………..8
II-3. Mesures de performances d’un moteur de
recherche……………...9
III- AUTRES OUTILS BASES SUR
L’UTILISATION DE MOTEURS DE RECHERCHE ……………………………………………………………………………10
III-1.
Les méta-moteurs………………………………………………………………..10
Ø Les
méta-moteurs en ligne…………………………………………………………10
Ø Les
méta-moteurs clients…………………………………………………………..11
III-2.
Les outils de recherche automatique……………………………………12
IV- LES TECHNIQUES D’INDEXATION………………………………………….13
IV-1. La technique d’indexation en texte intégral ………..………………….13
Ø Exclusion des mots vides de
sens………………………………………...………..13
Ø L’indexation des mots……………………………………………………………..14
Ø Calcul de la fréquence
d’apparition………………………………………………14
Ø Calcul de la localisation…………………………………………………………...14
Ø Création d’un index inversé………………………………………………………14
IV-2.
L’indexation par mots clés
………………………………………………….15
IV-3.
L’indexation par Thésaurus
…………………………...……………………16
IV-3.1 Description et
exemple………………………………………………………..16
ØDescripteurs,
ou termes préférentiels, ou termes autorisés………………16
ØTermes
non-descripteurs, ou synonymes, ou termes exclus……………...16
Ø
Structure du Thésaurus……………………………………………………16
ØConséquences au niveau
de l’indexation………………………………….17
ØConséquences au niveau
de la recherche………………………………….17
ØExemple du Thésaurus du
MeSH………………………………………….17
IV-3.2 Avantages et
inconvénients de la méthode d’indexation contrôlée par thésaurus par rapport à
la méthode d’indexation libre du texte intégral…………18
VI-4.
La méthode linguistique d’indexation…………………………………...19
IV-4.1 Introduction
et comparaison par rapport aux méthodes d’indexation
précédentes……………………………………………………………………………19
IV-4.2 Principes
des techniques linguistiques d’indexation……………………………………………..…………..….20
1) Le niveau morphologique……………………………………………...20
2) L’analyse syntaxique…………………………………………………..21
3) L’analyse
sémantique……………………………………………..…...22
IV-4.3
Deux niveaux d’utilisation des techniques linguistiques……………………24
ØApproche privilégiant l’analyse linguistique au
niveau de l’indexation…………………………………………………………………….24
ØApproche privilégiant l’analyse linguistique au
niveau de la recherche……………………………………………………………………….24
IV-4.4 Comparaison
de l’approche privilégiant l’analyse linguistique au niveau de l’indexation et
de l’approche privilégiant l’analyse linguistique au niveau de la
recherche……………………………………………………………………………....25
V- LES MODES DE
RECHERCHE …………………………………………….……26
V-1. Le mode requête en langage booléen……………………………….……26
Ø Les opérateurs booléens……………………………………………………26
Ø La syntaxe…………………………………………………………………...26
ØLes opérateurs de proximité……………………………………….…….…27
Ø L'utilisation des parenthèses………………………………………………27
Ø La recherche par zone……………………………………………………...27
ØLa troncature………………………………………………………………..28
ØLe mode recherche avancé…………………………………………………28
ØRecherche floue……………………………………………………………..28
Ø La technique d’expansion de requête …………………………………….28
Ø La recherche par question…………………………………………………29
Ø La recherche par similarité de
document…………………………………29
ØLa recherche par le sens des mots………………………………………….29
Ø Un mode de recherche prenant en compte la connotation
du discours et autorisant une recherche sur des groupes nominaux……………………….30
Ø Le mode recherche en langage naturel……………………………………31
VI-1. Les méthodes de tri utilisées……………………………………………….32
VI-1.1 Le tri par pertinence…………………………………………………….33
VI-1.2 Tri par
popularité ………………………………………………………..34
ØLa méthode basée sur la co-citation ………………………………………34
ØLa méthode
basée sur la mesure d'audience ………………..…………….34
VI-2. Les outils
d’affinage des résultats……………….………………………..38
VI-2.1
L’utilisation des réseaux
sémantiques ……………..………………..38
Ø Exemple du réseau sémantique spécialisé du
projet UMLS……………………..38
Ø Exemple de réseau sémantique dans le cas du vocabulaire courant……………39
Ø
Live Topics………………………………………………………….………………39
CONCLUSION…………………………………………………………………………………….41
BIBLIOGRAPHIE
REMERCIEMENTS
Je remercie le tuteur de ce sujet, Mathieu LAFOURCADE pour
m’avoir guidé dans mes recherches et pour m’avoir reçu au LIRMM afin
d’effectuer ensemble les corrections nécessaires à la finalisation de ce
rapport.
Je tiens également à
remercier Olivier MASSIOT (Responsable
de la R&D de la société DATOPS), pour avoir été disponible pour répondre à
mes nombreuses questions.
RESUME
Le développement des réseaux locaux et de l’Internet
a totalement libéré l’accès à l’information. Chacun peut désormais consulter au
gré de ses besoins les documents stockés par centaines de giga-octets dans les
bases de données de l’entreprise ou sur les serveurs Web répartis dans le
monde.
Cependant la masse des données accessible est
désorganisée et en pleine expansion.
Les outils de recherche doivent continuellement
s’adapter à cet univers en pleine évolution.
Ceux-ci doivent satisfaire l’utilisateur aussi bien
en terme de pertinence que d’exhaustivité de l’information retournée.
Ce rapport présente les principales technologies
utilisées par les moteurs de recherche pour atteindre cet objectif.
Mots clés :
moteur de recherche, indexation, hyper-texte,
linguistique, sémantique, ontologie, requête, classement, pertinence
CONVENTIONS
TYPOGRAPHIQUES
[1] Introduit la référence [1]
dans la partie bibliographique de ce rapport
Remarque : L’annexe 1
de ce rapport est une liste des url des moteurs de recherche cités qui n’ont
pas de référence ou d’url directement précisée dans le texte de ce rapport.
La problématique actuelle, en terme de gain de connaissance, n’est plus comme par le passé d’accéder à l’information mais de s’y retrouver : « Trop d’informations tue l’information ». C’est le paradoxe qu’a fait naître le développement des Nouvelles Technologies de l’Information et de la Communication (NTIC).
Internet qui à l’origine était un outil d’échange de
connaissances réservé au domaine scientifique s’est développé progressivement
vers un espace informationnel ouvert. Tout le monde peut maintenant accéder à
l’information mais aussi en déposer. Le rythme de croissance étant estimé à un
million de pages supplémentaires par jour, le web totalise à l’heure actuelle
quelques milliards de pages.
Face à cela les données sont de plus en
plus hétérogènes aussi bien en terme de support que de connaissance, sans
compter les problèmes de multilinguisme. Et qu’en est il de la structure ?
Si tant est qu’on puisse la définir, celle-ci est en perpétuelle
mouvance : les url qui sont les seul moyens d’accès aux pages,
apparaissent et disparaissent. De plus un certain nombre de ces url est
difficilement accessible.
Un besoin de classification de cette masse
informationnelle a fait naître des outils comme les annuaires (e.g. Yahoo www.yahoo.fr ). Ceux-ci en s’inspirant d’une
logique documentaire essayent de ranger les sites dans des répertoires
thématiques. Dans ces systèmes le référencement des sites est manuel. Le nombre
de site est donc limité. Ceci réduit donc ce qui fait le charme d’Internet
c’est à dire l’exhaustivité.
Les moteurs de recherche proposent donc la solution
complémentaire. La recherche est basée sur le contenu des documents à partir de
requêtes formulées par l’utilisateur dans le but de rapatrier les url
dynamiquement.
La problématique de ces outils sera alors de trouver
un bon compromis entre l’exhaustivité et la précision en terme de réponse.
Ce rapport présente en première partie une vision de la structure du web et la nature des documents qu’il contient. Les moteurs de recherche pour être véritablement performant doivent s’adapter à ces paramètres. La deuxième partie est une courte description des annuaires et une présentation du principe général de fonctionnement des moteurs de recherche et de la mesure de leur performance. La troisième partie présente d’autres outils qui utilisent les moteurs de recherche, tel que les méta-moteurs et les agents de recherche automatique qui pour ces derniers sont utilisés dans la constitution de bases de connaissances sur un sujet. En quatrième partie l’aspect technique est abordé en expliquant et comparant les différentes méthodes d’indexation sur lesquelles peuvent se baser les moteurs. Il faut préciser que certaines de ces méthodes d’indexation ne sont véritablement efficaces qu’utilisées par des moteurs sur le contenu d’un site spécialisé. La cinquième partie est un éventail des différents mode de recherche que peuvent proposer les moteurs à l’utilisateur. Enfin en dernière partie les principales méthodes de tri et d’affinage des résultats issus des requêtes des utilisateurs sont décrites.
I -
LES DOCUMENTS DU WEB ET SA STRUCTURE : IMPACT SUR LE TRAVAIL DES MOTEURS
DE RECHERCHE
Sur le Web, une page ou un document correspondent à un fichier écrit principalement au format HTML (Hyper Text Markup Langage), langage de description de données multimédias affichées par les logiciels « navigateurs» (ou browsers en anglais), comme Netscape Navigator ou Microsoft Internet Explorer.
Le nom du fichier HTML est du type Document.html,
et son adresse (appellée URL pour Uniform Ressource Locator) ressemble à
ceci : http://www.serveur.fr/Repertoire/SousRepertoire/Document.html
A noter que dans le nom du serveur, le dernier terme
indique le pays (.fr pour France) ou le type d’entreprise ou d’organisme
délivrant l’information (par ex .org pour organisation
à but non lucratif, .com pour organismes à but commercial).
HTTP (Hyper Text Transfert Protocol) est le protocole
de communication, entre un navigateur (le client) et un serveur connecté sur
Internet, permettant le transfert des pages Web. Il existe d’autres protocoles
sur Internet, comme le protocole FTP qui permet de télécharger des fichiers à
distance. De même qu’il existe d’autres applications susceptibles de détenir de
l’information : forums de discussion (newsgroups) et liste de diffusion
(mailing-lists).
Dans un document HTML, on trouve tous les éléments nécessaires à l’affichage des informations : texte et formatage (gras, italique, taille relative des caractères les uns par rapport aux autres), nom et adresse des images et illustrations, texte des liens (mots en couleurs et soulignés) et adresses nommées hyperliens vers lesquelles l’utilisateur sera dirigé s’il clique dessus, etc.
Les moteurs et les annuaires sur le net qui effectuent
leur recherche sur le Web à partir des documents HTML travaillent pour élargir
les fonctionnalités de recherche à d'autres formats de fichiers que le HTML.
En tant que
pionnier, Google a depuis 1998
ajouté à son moteur la possibilité d'indexer plusieurs fichiers différents de
l'html, tels que les images (gif ou jpg), les documents PDF, TXT, PostScript,
les applications de la suite Microsoft Office et d'autres formats avec lesquels
nous tous travaillons régulièrement. Il est vrai que plusieurs autres outils de
recherche incluent aujourd'hui des formats de fichiers différents de l'HTML,
mais Google reste celui qui pour premier les a introduits et a constamment
agrandit la gamme des extensions supportées, arrivant ainsi en début 2002 à
compter environ 2 milliards de documents indexés. Par exemple pour faire
uniquement une recherche sur les documents
pdf il suffit d’ajouter filetype:pdf aux critères de recherche.
I - 2 Eléments de structure des documents HTML (document 1)
I-2-1 Les tags classiques
Le document :
Un document HTML est inclus entre les deux balises
<html> et </html>.
L’en-tête :
Un document bien formé doit comporter un en-tête et un
corps. L’en-tête est placé entre les balises : <head></head>.
L’en-tête peut contenir divers éléments comme le titre de la page ou diverses
indications concernant son contenu qui peuvent être contenu dans des méta-tags.
Le titre :
Le titre est placé entre les balises <title> et </title>. Celui-ci est souvent utilisé par les robots des sites de recherche pour déterminer le classement des sites indexés. Ainsi, un site contenant un mot donné dans le titre sera mieux classé par rapport à ce mot que si ce dernier figurait simplement dans le corps du document.
Le corps :
Le corps du document est inclus entre les tags
<body> et </body>.
I-2-2 Les méta tags
Les balises META sont des balises HTML permettant d’indiquer
aux moteurs de recherche un certain nombre d’informations sur le contenu d’une
page Web. Le terme META signifie METADATA, soit « l’information sur
l’information ». Seules 10 à 20 % des pages Web contiendraient ces
indications.
Voici
quelques exemples de balises META (voir aussi document 1 page
précédente) :
- <Meta name= " Author
" content = "nom de l'auteur ou des auteurs de la page">
- <Meta name= " keywords " content = "liste de mots clés
séparés par une virgule">
- <Meta name= " description " content = "résumé du contenu
de la page, texte pris en compte par la majorité des moteurs de recherche qui
affichent ce texte (les 100 premiers mots) lors de recherches sur les moteurs">
- <Meta name= " Robots " content = "indique au robot s'il
doit indexer la page (index ou noindex) et s'il doit indexer ou non les pages
liées (follow, nofollow)"> : ceci permet de cacher aux utilisateurs
non concernés tout ou partie d'un site.
Remarque : Certains concepteurs de sites utilisent les mots clés
de manière abusive en les multipliants dans l’espoir d’être mieux référencés
par les moteurs ; cependant certains moteurs de recherche les refusent
d'office au-delà d'un certain nombre (si on cite plus de huit fois le même mot
clé, le moteur considère que l’on tente de "polluer" (spammer) ses
index et la page est déclassée à la pondération des réponses).
Limites
des balises META : Tous les
moteurs de recherche ne les prennent pas en compte (Excite ou WebCrawler, par
exemple). Lycos et NorthernLight indexent le texte des balises mais n'affichent
pas la zone description dans leurs résultats. Infoseek, HotBot et AltaVista
indexent par contre, pour leur part, tous les mots clés de la balise Keywords
et affichent le contenu de la balise Description dans leurs résultats. Dans le
cas d'AltaVista, l'utilisation de ces balises est limitée à 1024 caractères.
I-3 Structure du Web et accessibilité des documents
I-3-1 Une structure en nœud papillon
Pendant de longues années, l’idée couramment admise était que le Web visible (indexable par les moteurs de recherche), à l’image d’une toile d’araignée, était composé de pages bien connectées entre elles. En partant d’un certain nombre d’URLs bien choisies, les robots des moteurs de recherche devaient donc être capables de sillonner le cyberespace et de rapatrier la quasi-totalité des pages dans leur index, à l’exception, bien sûr, des pages crées juste après leur passage.
Cependant une étude menée par Altavista, Compaq
et IBM a conduit à une représentation graphique dite en "noeud papillon"
du Web mondial [2]. Elle montre
l'existence de différentes régions rendant la navigation sur le Web difficile,
voire impraticable. Les recherches précédentes, basées sur de simples
échantillonnages du Web, conduisaient à un haut degré de connectivité entre les
sites. Au contraire l'analyse de plus de 200 millions de pages Web prouve que
le Web est divisé en quatre grandes zones. On a pu constater aussi qu'un nombre
impressionnant de sites était inaccessible par l'absence de liens hypertextes.
Or, ces liens sont ce qu'un internaute utilise le plus au cours de ses
navigations sur le réseau.
La théorie du "noeud papillon" permet
d'appréhender l'organisation complexe du web (document 2) :
-
La partie centrale
(SCC-strongly connected component – sur le document 2) est constituée du
« noyau ultra-connecté » et contient moins d’un tiers des pages Web
(28 %). La navigation y est aisée, car chacune des pages est reliée aux autres
par des chemins de liens hypertexte. Ce noyau compact constitue le coeur du
réseau Internet. C’est lui qui permet de passer, par clics successifs, de
n’importe quelle page du IN vers une page du OUT. Ce sont les pages du coeur
que les robots des moteurs de recherche indexent en priorité et c’est à partir
de leurs liens qu’ils explorent le Web.
-
La partie gauche (IN)
contient les pages d’origine et représente environ un cinquième du réseau
(21%). Ces pages offrent des liens vers le coeur du Web, mais l’inverse n’est
pas vrai ; on trouve dans cette catégorie, par exemple, les pages de
moindre intérêt pour la communauté des netsurfers (certaines pages personnelles
…) ou les pages de création récente, qui n’ont pas été reconnues par leurs
pairs et vers lesquelles ne pointent encore que peu de liens.
-
La partie droite (OUT)
correspond aux pages de destination ; elles représente également un
cinquième du réseau. Ces pages sont accessibles depuis le coeur du Web, mais
aucun retour n’est possible. On trouve dans cette catégorie, notamment, les
sites commerciaux (site d’entreprises, de commerce électronique…), vers
lesquels pointent de nombreux liens, mais qui, eux, n’en proposent pas, ou seulement
en interne.
-
Une dernière zone,
représentant également un cinquième du Web (Tendrils), est composée de pages
non connectées au coeur du réseau. Ces pages sont accessibles depuis les pages
d’origine et/ou donnent accès aux pages de destination.
-
Enfin, près de 10 % des
pages Web sont totalement déconnectés des autres pages.
Ces résultats devraient permettrent une meilleure
connaissance de la topographie du Web et donc améliorer le travail des robots
des moteurs de recherche.
I-3-2 Le Web
invisible
Parallèlement au Web visible, composé de sites en
accès libre offrant des pages reliées entre elles, il existe un Web invisible
dont le volume est bien plus important et qui comprend :
- Les sites Web
construits autour d’une base de données, interrogeable via un formulaire
de recherche et qui donc génèrent les pages dynamiquement ou bien
interrogeable via un formulaire de recherche interne.
- Les divers sites où
il est nécessaire de s’identifier préalablement.
- Les sites offrant
des fichiers dans certains formats non reconnus par les robots
- Les pages Web qui
contiennent la balise [no robot]
La société BrightPlanet <www.brightplanet.com> préfère les
appellations de Deep Web, qu’elle oppose à « Surface Web » (document 3). Pour elle en effet, le Deep Web n’est
pas invisible; il est certes ignoré par les moteurs de recherche classique,
mais les nouveaux outils de recherche offline (et en particulier LexiBot <http://www.lexibot.com/>,
qu’elle développe), interrogent ses ressources. Lexibot
est en fait un métamoteur qui interroge des moteurs de recherche mais également
des ressources du Web invisible comme des bases de données, pouvant lancer des
douzaines de requêtes simultanées.
Pour sensibiliser les internautes aux richesses de ce
gisement d’informations, la société BrightPlanet a tenté de comparer le type de
sites et le nombre de documents disponibles sur le Web visible et le Web
invisible. Elle a pour cela analysé le contenu des sites recensés par sa base
CompletePlanet.com (www.completeplanet.com),
qui décrit plus de 38500 ressources du Web invisible. Elle a ensuite comparé
ces résultats avec ceux obtenus par le NEC Research Institute sur le Web
visible.
Les résultats de ces comparaisons sont parus fin juillet 2000, dans une étude intitulée The Deep Web : Surfacing Hidden Value [3] ; et ils sont surprenants. D’après les auteurs, le Deep Web contient plus de 550 milliards de documents ; il est donc 250 fois plus vaste que le Surface Web, si l’on compare les chiffres de BrightPlanet.com avec ceux de Cyveillance, publiés également en juillet 2000. Le nombre total de sites du Web invisible dépasse les 200 000, sachant que plusieurs bases accessibles depuis la même URL, comme les diverses bases de Dialog <www.dialogweb.com>ou de Lexis-Nexis <http://www.litec.fr/> par exemple, sont comptées pour un site ; d’autre part, et c’est une surprise, 95 % de l’information du Deep Web est accessible librement. Les bases du Deep Web enfin selon les auteurs fournissent plus d’informations de qualité que les sites du Surface Web.
Il ressort finalement de ces diverses études que :
-
les moteurs n’ont qu’une
indexation partielle du Web visible ;
-
le volume du Web visible
est très inférieur à celui du Web invisible ;
-
les sites les plus
riches appartiennent au Web invisible
Heureusement, il existe des outils spécialisés qui
identifient et interrogent les sites du Deep Web comme Lexibot précédemment
cité.
II- ANNUAIRE ET MOTEURS DE RECHERCHE : PRINCIPE GENERAL
DE FONCTIONNEMENT
Il est important de rappeller les différences fondamentales qui existent entre les annuaires (également appelés répertoires ou index) et les moteurs de recherche ou robots. Ces deux familles d’outils représentent les bases de la recherche sur le Net, même s’il est vrai que chacune tend à évoluer vers le portail.
Si l’on compare le Web à une immense bibliothèque
rassemblant des millions d’ouvrages (chaque ouvrage étant un site Web), les
annuaires de type Yahoo <www.yahoo.com>
(document 4)ou Nomade <www.nomade.fr> peuvent être comparés au
catalogue de cette bibliothèque, fonctionnant sur le principe des banques de
données bibliographiques.
Les ouvrages/sites sont indexés avec leur titre et un très bref descriptif dans des rubriques et sous-rubriques. C’est une équipe de « cyberdocumentalistes » qui est chargée de tester les centaines de sites proposés chaque jour aux annuaires par les éditeurs, de vérifier les informations données en les complétant éventuellement et de classer les sites dans les catégories appropriées. Comme dans une base bibliographique, il y a un travail humain d’indexation derrière chaque référence.
Les annuaires proposent dès leur écran d’accueil une
liste de rubriques et de sous-rubriques et il suffit au visiteur de cliquer sur
un thème, puis sur des sous-thèmes successifs, pour afficher une liste de sites
répondant à sa question. Un choix nettement plus simple, pour le néophyte en particulier,
que celui des mots-clés qu’il faut indiquer à un moteur de recherche, mots-clés
qui doivent être précis si l’on veut pas être noyé sous une avalanche de
résultats. A cette simplicité d’utilisation, s’ajoute une autre qualité :
la liste des sites sélectionnés en bout de course est en général pertinente.
Ceci n’est pas surprenant, puisque l’indexation des sites est réalisée
manuellement par l’équipe éditoriale de l’annuaire.
En complément des diverses catégories, les écrans d’accueil des annuaires disposent le plus souvent d’une zone de saisie permettant d’effectuer une recherche par mots. La requête est alors lancée sur l’intégralité du catalogue, c’est-à-dire sur les catégories, les titres et les brèves descriptions des sites. Lorsque l’on lance une recherche par mots dans un annuaire, c’est un peu comme si on lançait une requête par mots sur les titres et les résumés des ouvrages d’une bibliothèque.
Quelques défauts : ils leur sont reprochés un manque d’exhaustivité de
par leurs mécanismes d’enrichissement (augmentation de la base répertoriée par
inscription des auteurs), ainsi que des insuffisances en cas de recherche
thématique très précise (nom de produit, de personne …).
Précurseurs dans le domaine de la recherche et de l’indexation de l’information sur le Web, les répertoires fournissent une réponse précise rapide et complète lorsque le besoin est lui-même simple et bien défini. Mais enfin de permettre des recherches plus globales, ils ont été rapidement complétés par des « moteurs de recherches ».
II-2. Les moteurs de recherche
II-2-1 Définition
On parle de moteur de recherche ou de robot
pour un dispositif technique qui fait des recherches sur un ensemble de
données. Dans le cas d’Internet, c’est un automate qui va utiliser le contenu
des pages HTML comme données sur lesquelles il va faire ses recherches. A
partir de ces éléments, le robot va stocker des données qui pourront être
réutilisées au moment de l’interrogation. L’interrogation d’un moteur de
recherche n’est plus dès lors qu’un accès à une base de données préalablement
remplie et organisée, interfacé par une page Web. Le robot, lui, est lancé de
façon invisible aux utilisateurs à des dates périodiques pour maintenir ses
tables à jour.
Cependant l’utilisation de ces outils ne se limite pas
à l’Internet et beaucoup sont utilisés pour faire de la recherche
d’informations limitée au contenu d’un site Intranet. C’est typiquement le
genre de logiciel qui est utilisé lorsqu’un site web offre des fonctionnalités
du type « rechercher sur ce site : ». Altavista par exemple
propose à la fois une version en ligne < http://fr.altavista.com/>
pour faire une recherche sur la totalité du Web mais aussi une version Intranet
payante nommée AltaVista Search Engine 3.0 [1].
D’autres entreprises commercialisent des moteurs adaptés uniquement à la
recherche sur site Intranet. C’est le cas par exemple de Sinequa avec le
logiciel Intuition [13].
On peut cependant se procurer certains moteurs de
recherche et d’indexation gratuitement. Un des plus populaire est le moteur
htdig (open source) également utilisé pour faire de la recherche sur un site
web donné. L’annexe
2 référence et
décrit un certain nombre de ces outils gratuits dont htdig.
II-2-2 Historique
WebCrawler a été un des premiers moteurs de recherche à être lancé sur le marché. Développé dans un projet de recherche de l’Université de Washington au début de l’année 1994, il a été une véritable réussite commerciale (car correspondant à un réel besoin des utilisateurs et aux ressources publicitaires générées). Au commencement de son exploitation, sa base de données contenait des informations sur 6000 serveurs Web. Son succès en a fait un outil très vite utilisé et dès la fin 1994, le service recevait plus de 15000 requêtes par jour. Depuis de nombreux moteurs ont été mis en circulation : Lycos, Altavista, Lockace, Hotbot, etc. Très nombreux aujourd’hui, seuls certains sont souvent utilisés.
II-3 Le fonctionnement d’un moteur de recherche
Pour une
majorité des moteurs, le principe de fonctionnement est généralement le même.
Le moteur collecte les données, les archive, les indexe, et les restitue par
ordre de pertinence. Il est composé de plusieurs éléments : un robot qui va
collecter les données, un moteur d'indexation, et un moteur d'interrogation (document 5).
Ø La collecte des données
Les moteurs
utilisent un robot souvent appelé spider ou crawler qui balaie
sans relâche le web et éventuellement les newsgroups pour en archiver
intégralement le contenu dans une base de
données.
En principe
le robot suit tous les liens qu'il rencontre, mais cet agent peut utiliser
différent types d'algorithmes pour allez chercher le maximum de pages et c'est
ce qui explique les différences de réponses de deux moteurs pour une même
requête. Actuellement la vitesse moyenne des robots est de 400 pages par
secondes sachant qu’un crawler travaille en parallèle avec d’autres crawler.
A chaque
fois que le crawler rencontre un lien, il compare cette adresse aux adresses
connues, il a alors 3 possibilités :
-
l’adresse est inconnue
-
l’adresse est connue
mais la date de la dernière visite sur la page est ancienne
-
l’adresse est connue
mais le date de la dernière visite sur la page est récente
Dans les
deux premiers cas, le crawler ajoute l’adresse de la page comme page à
archiver.
Le problème de ce type d'algorithme est la croissance importante de nombreux sites "isolés", c'est à dire sur lesquels ne pointent aucun lien venant d'autres pages ou sites web, et ceci entraîne un nombre important de sites non répertoriés par les moteurs. L'immensité de la tâche à accomplir explique qu'un certain délai soit nécessaire au renouvellement de la base de données ainsi crée et ceci explique que l'on puisse donc trouver sur des moteurs des pages qui n'existent plus. A l'inverse, plusieurs semaines voire plusieurs mois peuvent être nécessaires avant qu'une nouvelle page soit archivée. Un moyen d'accélérer les choses est alors d'indiquer manuellement (soumission) au robot l'adresse de la page "à visiter".
Sur le document 6 est
présenté un tableau comparant la quantité approximative de pages réellement
indexées par différents moteur de recherche avec la fréquence de mise à jour de
ces index (en date d’octobre 2002) [10].
Ø L’indexation
Le robot renvoie les informations collectées au moteur d’indexation pour qu’elles soient analysées. Ce dernier construit alors un index des mots rencontrés et stocke l’ensemble dans une base de données. On parle généralement d’indexation automatique. Cette liste de termes répertoriés est relié aux adresses des pages correspondantes sur le web. Grâce à un pointeur, ces pages peuvent être retrouvées facilement.
Ø Recherche et présentation des pages
Lors d'une
requête, le moteur d'interrogation analyse la question posée par l'internaute,
la traduit en un ensemble de mots, va rechercher les documents correspondants
et les propose par ordre de pertinence décroissant. C'est bien sûr la méthode
de calcul de la pertinence utilisée par le moteur qui est à prendre en compte
pour optimiser le référencement. Les critères de pertinence les plus souvent
rencontrés sont :
- La présence des mots clés dans
le titre, dans l'en-tête, dans le contenu de la page et éventuellement
dans les méta-tags
- La position (haut de page) des
mots clés dans la page
- La répétition (jusqu'à un
certain point) des mots clés.
C'est le
principe de localisation et de fréquence.
Cependant
il existe d'autres méthodes reposant sur des principes tout à fait différents
et indépendants du contenu des documents. Citons par exemple le tri par
popularité utilisé par Google.
Ainsi les
méthodes employées pour déterminer la pertinence d'un mot clé sont différentes
d'un moteur à l'autre, et c'est ce qui explique qu'une même page puisse avoir
une qualité de référencement très variable d'un moteur à l'autre sur le même
mot clé.
III- AUTRES OUTILS
BASES SUR L’UTILISATION DE MOTEURS DE RECHERCHE
III-1. Les méta-moteurs
Les méta-moteurs sont des outils qui, pour
une même requête interrogent plusieurs moteurs de façon simultanée, rapatrient
les résultats, les synthétisent et proposent un récapitulatif des réponses
données. Le fonctionnement des méta-moteurs est décrit sur le document 8.
Les méta-moteurs se distinguent entre eux par :
·
le nombre et la nature
des moteurs interrogées ;
·
le traitement des
résultats : celui-ci es très variable, allant du listing brut au classement par
outils de recherche, jusqu’à la fusion avec élimination des doublons pour
certains.
Inconvénients des méta-moteurs : Il n’est pas permis, sur ces services, d’utiliser les
fonctionnalités avancées des moteurs de recherche (notamment les fonctions de
type host: , url: , title: d’Altavista, par exemple), tout simplement parce qu’elles varient
grandement selon les outils interrogés. D’autre part les méta-moteurs font la
synthèse de résultats fournis par plusieurs moteurs différents, classant chacun
leurs résultats de façons différentes, sans utiliser les mêmes critères de pertinence.
Ensuite les méta-moteurs ne récupèrent qu'un nombre limité de résultats de
chaque outil interrogé : entre 10 et 50 au maximum. De plus ils n'attendent les
résultats que pendant un temps limité aussi (le time out) qui est cependant
paramétrable.
Leur utilisation est efficace dans le cadre de
recherche sur des sujets très pointus où l’information est plutôt rarissime. Si
l’on utilise ces outils à l’aide de termes plutôt généraux on risque de générer
beaucoup d’informations non pertinentes. Pour palier à cela certains de ces
outils comme Copernic <http://www.copernic.com/> permettent
d’effectuer une deuxième recherche plus précise sur uniquement le résultat des
documents rapatriés avec la première requête. On approche ainsi l’information
pertinente par affinage successif.
Il existe deux grands types de méta-moteurs selon
qu'on les interroge à distance ou qu'on installe un logiciel sur son poste de
travail.
Ø Les méta-moteurs en ligne
Un serveur sert d'intermédiaire entre l'utilisateur et
les outils interrogés. Un formulaire en général limité permet d'exprimer sa
requête. Ce type de méta-moteur est surtout intéressant pour sa rapidité à
explorer de nombreux outils de recherche, mais les fonctionnalités en sont en
général très limitées.
·
DOGPILE < http://www.dogpile.com/>
DogPile, lancé en 1997,
supporte jusqu'à vingt-cinq outils de recherche. Il offre le choix entre une
recherche de pages web, de messages des News (Usenet), de fichiers, de dépêches
d'agences de presse, d'images et de fichiers mp3.Le résultat est classé
uniquement par outil de recherche, sans traitement de doublons.
·
IXQUICK <http://www.ixquick.com/>
Ixquick affirme s'adresser à
chaque outil de recherche dans leur syntaxe propre, ce qui lève un des
principaux reproches fait aux méta-moteurs.
·
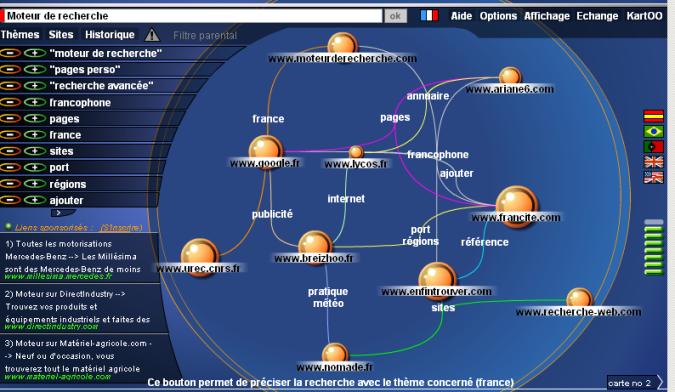
KARTOO <http://www.kartoo.com/>
Kartoo, lancé en mai
2001 par une société française, se distingue par la présentation des résultats
sous forme de carte de connaissance publiée en technologie Flash ou en HTML.
·
METACRAWLER <http://www.metacrawler.com/>
C'est le premier outil
de ce type, développé à l'Université de Washington par Erik Selberg et Oren
Etzioni. Il organise les résultats en une liste triée par pertinence après
avoir éliminé les doublons.
·
PROFUSION <http://www.profusion.com/>
ProFusion utilise la
technologie d'IntelliSeek, spécialiste du web invisible. Il interroge plus de
mille sources dont de nombreux outils de recherche et plus de cinq cents
sources du web invisible.
Ø Les méta-moteurs clients
Dans ce cas, il faut
télécharger un logiciel et l'installer sur son poste de travail. En général,
les fonctionnalités sont plus importantes que dans le cas précédent. Il est en
particulier possible de planifier des recherches, ce qui s'avère intéressant
pour la veille et les rapproche de la catégorie des outils de recherche décrite
dans le paragraphe suivant. Cette famille de logiciels est en plein essor et
les produits nouveaux sont nombreux. En voici quelques-uns :
·
COPERNIC <http://www.copernic.com/>
(voir également document 9)
C’est le plus populaire de
ces outils. Une fonction de recherche par mots clés sur les résultats obtenus
est disponible. Pour la consultation hors ligne, il est possible de télécharger
tout ou partie des documents trouvés. Un historique détaillé des résultats,
classés dans des dossiers, peut être créé et mis à jour au fur et à mesure.
Autres outils :
·
GLOOTON <http://www.glooton.com/>
Créé en octobre 2000 par trois ingénieurs, il revendique sa spécificité par rapport à Copernic et Sherlock en se voulant beaucoup plus paramétrable, à l'aide de plugin disponibles sur le web. Il est gratuit
·
STRATEGIC FINDER <http://www.digimind.com/>
Strategic Finder produit par Digimind, société spécialisée sur le métier de la veille stratégique fondée en 1998. Strategic Finder permet également de traduire automatiquement votre requête dans le langage de n'importe quel moteur de recherche sur Internet. Pour cela l'ensemble des sources d'informations (plus de quatre mille) est rassemblé en catégories. Il propose toute une série de plugin pour rechercher par thème sur des outils de recherche spécifiques.
III-2. Les outils de recherche automatique
Les outils de recherche automatique d’information n’ont d’automatique que l’actualisation des recherches. En effet, pour une utilisation de tels outils, il est indispensable de les paramétrer et de les « rendre intelligent » avant même de commencer la première recherche.
En résumé ces outils permettent de récupérer, stocker et gérer automatiquement et de manière pertinente la grande quantité d'informations disponibles sur Internet et dans les intranets en fonction des requêtes de l’utilisateur. Ce sont des outils adapté à la veille. Voici en détail l’ensemble des fonctions remplies dans le meilleur des cas par les logiciels de recherche automatique d’information (voir aussi document 10) :
- Effectuer les recherches sur
plusieurs sources : à partir d’une requête ou de profils complexe
(par domaine ou sémantique) il s’agit de rechercher les informations dans
le Web, Gopher, usenet, mailing list, en utilisant les moteurs de
recherche mais aussi des sites non référencés sur ces derniers.
- Sauvegarder les documents
trouver : consulter les sites qui répondent à la requête pour
télécharger la page et la sauvegarder temporairement sur le poste de
l’utilisateur.
- Réactualiser les recherches
sur les sources : réaliser un suivi dynamique du contenu dans le
temps en comparant les documents initiaux avec les nouveaux documents.
- Filtrer en amont ces
documents : comparer les mots de la page à l’aide d’une méthode
linguistique ou sémantique afin d’éliminer les documents qui s’éloignent
du contexte.
- Sauvegarder les documents
pertinents : après le filtrage précédent, il s’agit de constituer une
base de données contenant seulement des documents répondant au mieux à la
requête.
- Générer un résumé
automatique : extraire le sens ou simplement prendre les premiers
mots de chaque document.
- Indexer l’ensemble des
documents filtrés : créer un index en texte intégral et générer un
dictionnaire des mots contenus dans l’ensemble des documents.
- Filtrer en aval les
documents : comparer les documents par différentes méthodes
(sémantique, linguistique, synonimique) afin de définir des ensembles
homogènes de documents en sous-thèmes.
- Présenter les résultats :
mettre en valeur les synthèses sous forme de carte (mapping), d’arbre, de
représentation graphique (2D, 3D), résumé de synthèse, afin de les
exploiter rapidement.
- Diffuser les synthèses
automatiquement aux personnes concernées. Fournir un service à haute
valeur ajoutée dans la diffusion de synthèses de documents.
L’organisation
de ces différentes fonctions représentée sur le document 10 page précédente
montre que le processus n’est pas unique puisque certaines fonctions, comme le
filtrage par exemple, peuvent être éliminées de la fonction globale de
recherche automatique.
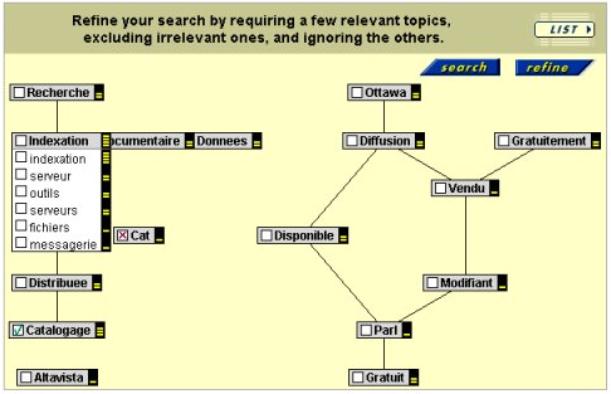
Le logiciel
Copernic (version 6 payante de Copernic Agent Professional [20]) possède la plupart des fonctionnalités décrites mis à
part la fonction d’aide à la décision. De plus, pour ce logiciel la recherche
en « langage naturel » n’est disponible que pour la version en
anglais. Pour obtenir la génération automatique de résumé il faut se procurer
en plus le produit également payant « Copernic Summarizer » [21].
Le logiciel
Pericles plus complet de la société Datops [16] est aussi un outil adapté à la veille. Il est cependant
différent de Copernic qui ne fait qu’interroger les ressources des autres
moteurs de recherche pour constituer sa base de documents. En effet le logiciel
de la société Datops doit se constituer en aval ses propre ressources de
documents indexés. Nous reviendrons plus en détail sur ce logiciel un peu plus
loin dans ce rapport (paragraphe V-2).
IV-
LES TECHNIQUES D’INDEXATION
Les techniques d’indexation permettent de définir les critères utilisables en recherche et leurs conditions d’exploitation. Les moteurs d’indexation génèrent leurs propres index et y appliquent leurs algorithme de sélection et de tri. Les technologies employées sont propres pour chaque moteur, même si les principes peuvent être un peu généralisés. Ceux présentés ici sont schématiques et ont pour but d’expliquer le fonctionnement général.
IV-1. La technique d’indexation en
texte intégral
Tous les mots contenus de la page sont
insérés dans l’index, c’est la méthode la plus fréquemment employé puisqu’elle
tient compte de l’intégralité du texte. Il s’agit alors de construire un
fichier d’index qui comprenne, comme entrées, tous les mots du texte à indexer.
Ø Exclusion des
mots vides de sens
Il y a dans le langage écrit de nombreux mots qui
n’apportent que peu de sens au texte, bien qu’indispensable à la compréhension.
L’indexation du texte , pour éviter d’encombrer les fichiers, pour éviter
d’encombrer les fichiers, ne prend en général pas en compte ces mots, lors de
l’indexation. Ces mots vides sont, entre autres, les articles, les conjonctions
de coordination, mais également les adverbes, les formes conjuguées des
auxiliaires qui sont présent en grand nombre dans les textes. Ainsi dans la
phrase « Mais que fait la police ? », le seul terme exploitable
en recherche est le terme « police », les autres sont considérés
comme des mots vides.
Traditionnellement, on élimine d’emblée ces mots lors
de la construction des index de la base d’information, en les rassemblant dans
un dictionnaire de mots vides. En général, les éditeurs de logiciel proposent
de tels dictionnaires dans les principales langues. On peut ajouter ou
supprimer des mots vides dans ce dictionnaire, à l’initialisation de la base,
et éventuellement, ultérieurement.
Ø L’indexation
des mots
Il s’agit de construire un fichier d’index pour chaque
document qui comprenne, comme entrées, tous les mots du texte à indexer, à
l’exception des mots vides. Dans le document 11 est présenté de manière simplifié le principe
général de l’indexation à partir de deux pages Web. Dans chaque INDEX page un poids
est associé à chacun des mots du document qui représentera un index de
pertinence. Dans notre exemple ce poids est calculé en fonction de deux
critères : la fréquence d’apparition
et la localisation des mots dans le document.
Ø Calcul de la
fréquence d’apparition
A chacun des mots de l’index de la page est associé son nombre d’apparition dans la page Web : c’est la fréquence du mot notée F. Dans certain moteur un seuil de fréquence d’apparition du mot est fixé pour que le mot soit présent dans l’INDEX page.
Ø Calcul de la
localisation
En plus de la fréquence les fichiers d’index peuvent comprendre davantage d’informations : on les appelle aussi index positionnels. Pour chaque page, l’information gérée dans le fichier d’index comprend outre la clé, la position du mot dans le texte (colonne E=En-tête,U=url,T=Titre,I=Image,M=Méta). Cette position du mot peut être gérée en absolu, c'est-à-dire que lors de l’indexation, le moteur calcule la position du mot dans le texte par rapport à son début.
Elle peut aussi être gérée en fonction de la structure du texte (comme dans le document 11). Nous avons vu au paragraphe I-2 (document 1) les différents éléments de structure d’une page Web et son influence dans le référencement des moteurs : plus fort poids pour les mots présents dans les titres, prise en compte des informations contenues dans les balises META. Dans le document on a qu’un champ M pour balise META mais on peut imaginer découper ce champs en plusieurs champs pour conserver les informations des balises META comme les champs Auteur, Mots clés, …
Ø Création d’un
index inversé
Une fois l’indexation des mots de chacune des pages
effectué il y a création d’un index global inversé qui va référencer pour
chacun des mots les documents dans lesquels ils sont présents avec le poids
associé. Plus le poids d’un mot sera important dans la page, mieux cette page
sera classée dans l’index associé au mot. Par la suite lors d’une requête faite
par un internaute et contenant ce même mot, les pages apparaîtront dans cet
ordre. Pour une requête à plusieurs mots, par exemple contenant les mots MOTEUR
et DOSSIER, le retour se fera dans l’ordre des pages contenant MOTEUR et parmi
celles-ci dans l’ordre des pages contenant les mots MOTEUR et DOSSIER.
Les informations sur la localisation des mots dans le
document peuvent également être reporté dans l’index inversé. Conserver le
champ TITRE pourra permettre à travers
l’interface du moteur d’interroger la base sur une requête du type title : Moteur qui consiste à rapatrier tous les documents qui
contiennent le mots Moteur
dans leur titre. De même, conserver le
champ URL pourra permettre à travers l’interface du moteur d’interroger la base
sur une requête du type url :
Moteur qui consiste à rapatrier tous les
documents qui contiennent le mots Moteur dans leur url.
Ces fonctionnalités de recherche sont disponibles par exemple pour les moteurs
de recherche Altavista et Google.
Une indexation encore plus fine peut consister à
définir dans un document la position du mot par le numéro de section, le numéro
de paragraphe dans la section, le numéro de phrase dans le paragraphe, et le
numéro de mot dans la phrase. On parle alors aussi d’index positionnel. Ainsi
le moteur de recherche ne se contente plus de retrouver le document pertinent
mais pointe également sur la phrase ou la portion de phrase qui constitue une
réponse à la question. A noter que certains moteurs proposent une mise en sur
brillance des mots qui constituent une réponse à la question.
Conserver l’information sur la position des mots
permet aussi des recherches relativement plus évoluées que celles qui portent
sur la seule présence de mots dans un texte. Par exemple : Si on interroge
une base d’information sur les Moteur de Recherche, vous pourrez préciser que vous souhaiter trouver des
textes où Moteur et Recherche sont l’un à côté de
l’autre. Pour cela il est possible d’utiliser l’opérateur NEAR avec par exemple les moteur Alta Vista et Lycos (voir
paragraphe V-I pour plus d’information sur cet opérateur). Sinon vous
obtiendrez des tas de texte qui traiteront par exemple de la Recherche sur les Moteurs à combustion …
Le document 12 synthétise les
variantes qui peuvent exister au niveau de l’indexation en texte intégral
utilisé par les moteurs de recherche du Web. Des informations sur la structure,
le formats, la gestion et la mise à jour des index sont également disponible en
annexe
3.
IV-2. L’indexation par mots clés
Il s’agit de construire comme précédemment
un index inverse de mots en comparant cette fois tous les mots trouvés à une
liste. Cette liste sera utilisée, non pas comme dans le cas précédent, pour
éliminer les mots vides, mais au contraire pour garder uniquement les mots du
texte qui lui appartiennent.
Cela relève à présent de l’indexation contrôlée (par
utilisation d’un lexique de mot) à l’inverse de la technique d’indexation par
texte intégral qui est une technique d’indexation libre. Cette liste de mots
clés peu correspondre à un vocabulaire normalisé correspondant à tel ou tel
domaine comme par exemple une liste de mots clés pour le domaine juridique. Les
termes extraits peuvent aussi être pondérés en fonction de leur fréquence
d’apparition ou de leur localisation. VERITY Information Server [12] propose une indexation de ce type.
IV-3. L’indexation par Thésaurus
IV-3.1 Description et exemple
Un thésaurus est un vocabulaire d’un langage
d’indexation contrôlé organisé formellement de façon à expliciter des relations
a priori entre des concepts.
Cela peut être des relations génériques-spécifiques
correspondant à des notions d’hyperonymie/hyponymie (véhicule est un
terme générique ou hyperonyme de voiture ; deux chevaux est
un terme spécifique ou hyponyme de voiture).
Cela peut être aussi des relations d’association
correspondant à des notions de synonymie (oculiste est un synonyme d’ophtalmologiste).
Un thésaurus est conçu en principe selon des normes et des conventions
internationales [5].
Ainsi comme avec la liste de mots clés, le thésaurus
va limiter la liste des mots extraits des textes qui seront utilisés dans
l’indexation. Cependant la différence est que cette liste de mots dans le cas
du thésaurus est structurée et tous les mots de cette liste ne pointent pas
vers des documents. En effet un thésaurus se compose de termes descripteurs et
de non-descripteurs. Seul les termes descripteurs sont utilisés dans
l’indexation.
ØDescripteurs, ou termes préférentiels, ou termes
autorisés
Ce sont des mots simples ou composés du langage
courant (généralement des substantifs ou des groupes nominaux), qui servent à
désigner les concepts représentatifs du contenu des documents, et qui sont
utilisés aussi bien pour l’indexation que pour les requêtes.
ØTermes non-descripteurs, ou synonymes, ou termes
exclus
Ils désignent des concepts identiques ou voisins de
ceux représentés par les descripteurs. Ils ne peuvent être utilisés pour
l’indexation, et renvoient chacun à un ou plusieurs descripteurs autorisés. Ils
ont pour rôle essentiel de guider les indexeurs dans leurs recherches.
Dans le document 13 on peut
observer les relations qu’entretient le mot fibre avec d’autres termes
dans le Thésaurus de Statistique du Canada [4]. Cet outil bilingue d’indexage et de recherche documentaire
entièrement structuré a été mis au point afin de permettre aux utilisateurs
d’accéder aux ressources d’information de Statistique du Canada en effectuant
une recherche par sujet. Dans le document 11 les termes descripteurs sont en
bleu soulignés. Les termes non-descripteurs tels que fibres chimiques et
fibres naturelles sont en vert.
ØStructure du Thésaurus
Dans le Thésaurus, les relations sont hiérarchiques
(termes génériques ou spécifiques), associatives (termes associés) ou
normatives (employer ou employé pour). Les définitions suivantes vous aideront
à comprendre les différentes relations structurelles présentées dans le
document 13 par rapport au terme fibres.
Terme générique : le terme générique du mot fibres
est situé au dessus de lui dans la hiérarchie. C’est un terme descripteur qui a
un sens plus général que celui du mot fibres.
Terme spécifique : les termes spécifiques du mot fibres
sont situés en dessous de lui dans la hiérarchie. Ce sont des termes
descripteurs qui ont un sens plus restreint que celui du mot fibres.
Terme associé : les termes associés au mot fibres
sont liés à lui par association et non par hiérarchie dans le thésaurus. Ce
sont des termes descripteurs dont le sens est proche de celui du descripteur fibres.
Terme employé pour : ce sont des termes
non-descripteurs qui entretiennent un lien d’équivalence avec un terme
descripteur. Ils permettent d’obtenir un descripteur (ici le mot fibres)
à partir des termes non descripteur (ici Fibres chimiques, Fibres
naturelles). Ceci permet d’utiliser des synonymes, des quasi-synonymes et
des variantes lexicales.
ØConséquences au niveau de l’indexation
Un document contenant un terme descripteur comme Fibres
est également indexé par défaut par son équivalent générique (dans ce cas Produit
textile comme indiqué dans le document 13 page précédente). Il est possible
que ce même document soit aussi indexé par l’équivalent générique de Produit
textile (ex : Produits manufacturés). Le nombre de niveaux
varie en fonction des thésaurus.
ØConséquences au niveau de la recherche
Par défaut le système va inclure les termes
spécifiques liés à un terme descripteur dans une requête. Par exemple si l’on
fait une requête sur le mot Produit textile, le système va nous proposer
en premier les documents contenant le mot Produit textile puis ensuite
des documents contenant le mot Fibres qui est un terme spécifique du mot
Produit textile. Le choix d’inclure les termes spécifiques dans la
requête peut éventuellement être paramétré. Par contre si l’utilisateur fait une
requête sur le terme Fibres
chimiques, le système va alors proposer
de faire une recherche sur le mot Fibres car Fibres chimiques n’est pas un terme descripteur.
ØExemple du Thésaurus du MeSH
Le MeSH (Medical Subject
Headings) [5bis]
]est le
thesaurus de la base bibliographique Medline, thésaurus de référence dans le
domaine biomédical. Il s’agit d’un schéma de classification hiérarchique
comprenant 19000 sujets-clefs et codes principaux, utilisés pour l’indexation
des bases de données crées par la bibliothèque nationale de médecine (National
Library of Medecine) avec la participation de l’Inserm pour la version
française.
Chaque article de Medline se voit attribuer entre 6 et
15 sujets-clefs, avec un maximum de 3 pour les thèmes clés de l’article. Les
articles sont indexés suivant le terme le plus spécifique, afin de garantir un
très haut degré de précision lors d’une recherche par sujet. Les mots-matières,
c’est-à-dire les termes couvrant les aspects fréquemment mentionnés d’un sujet
(par exemple effet secondaires ou thérapie) sont ajoutés aux
termes MeSH pour identifier clairement le thème principal de l’article.
Les Medical Subject Headings sont révisés et
actualisés en permanence par des spécialistes, maîtrisant chacun un domaine
médical spécifique. Leur travail consiste à rassembler les termes nouveaux au
fur et à mesure de leur parution dans des ouvrages scientifiques ou de leur
utilisation dans de nouveaux domaines de la recherche, à définir ces termes
dans le cadre du vocabulaire normalisé existant, et à recommander leur
inclusion dans MeSH. Ils reçoivent également des suggestions de la part de
documentalistes ou d’autres professionnels.
Sur le site de PubMed [6] (l’équivalent de la base de donnée Medline au NCBI), une
option intitulé MeSH Browser permet de trouver plus facilement des mots clés
MeSH pertinents pour la recherche d’articles scientifiques sur un sujet.
Voici un exemple de recherche dans le thésaurus du
MeSH :
L’utilisateur souhaite traiter la question : Douleurs
associées aux traitements des cancers du sein ?
Il doit tout d’abord saisir l’expression : breast
cancerdans la fenêtre de recherche. Puis après avoir cliqué sur le bouton Go, le système indique que le terme breast cancer n’est pas un mot
clé MeSH mais il affiche la fiche descriptive du terme MeSH équivalent : Breast
Neoplasms.
La fiche descriptive du terme comprend : la
définition, l’environnement sémantique sous la forme d’une arborescence (document 14). L’arborescence correspond à
l’affichage hiérarchique du terme dans le thésaurus du MeSH. Un terme MeSH peut
appartenir à plusieurs arborescences.
Le bouton ADD permet d’ajouter
le terme substitutif Breast Neoplasms à la requête. Par défaut PubMed
inclut dans la requête les termes spécifiques liés au terme descripteur proposé
(ici Breast Neoplasms). La requête est donc étendue. Il est cependant
possible de limiter la recherche à Breast Neoplasms.
Il existe une autre option qui est accessible par
l’hyperlien [Detailed
display] en haut de la page. Elle permet
par une liste de cases à cocher associées à des qualificatifs, de limiter cette
fois la requête à un aspect particulier comme : analysis, blood, blood
supply. La requête booléenne peut ensuite être envoyée dans PubMed pour la
recherche de références bibliographiques.
IV-3.2 Avantage et inconvénient de la méthode d’indexation contrôlée par thésaurus par rapport à la méthode d’indexation libre du texte intégral
Les relations d’équivalence d’un thésaurus permettent
de résoudre le problème de la synonymie, qui est contourné grâce à la relation
« terme préférentiel (descripteur) / terme non-descripteur »
permettant de distinguer un descripteur parmi un ensemble de synonymes et de
les relier entre eux.
Les relations hiérarchiques permettent également
d’utiliser une technique dite d’autopostage (de automatic posting >
autoposting) lorsque l’indexation est automatique : lors de l’indexation
des textes, elle complète les notions spécifiques à l’aide de leurs termes
génériques ; lors de l’indexation d’une question posée avec des termes
génériques, elle permet de la compléter avec les termes spécifiques.
La résolution du problème de l’ambiguïté lexicale de
la langue est réalisée par le choix de descripteur non ambigu. Ces ambiguïtés
sont générés notamment par les phénomènes d’homographies et de polysémies. Une
homographie entre deux mots est une identité accidentelle de mots d’origines
différentes. Une polysémie est un mot ayant plusieurs sens. Prenons l’exemple de
la phrase « Les poules du couvent couvent. » qui comporte deux
formes d’homographes. Dans un thésaurus on pourra utiliser le terme descripteur
monastère comme descripteur du mot couvent.
Ce problème n’étant évidemment pas résolu par une
méthode d’indexation libre c’est ce qui explique que les moteurs de recherche
basés sur une technique d’indexation par texte intégral génèrent ce que l’on
appelle du bruit dans leur résultat. Il y a bruit si le système propose
comme réponse à une requête des documents non pertinents, c’est-à-dire ne
répondant pas à la question. En effet, une requête sur les transports aériens
utilisant la chaîne vol peut entraîner la sélection de textes parlant de
cambriolages – ou d’oiseaux – étant donné qu’aucune levée d’ambiguïté n’aura été
faite pour différencier les emplois du substantif.
Parmi ses inconvénients il faut souligner la
complexité de la mise en œuvre de l’indexation par thésaurus et sa mise à jour.
Ceci oblige pour obtenir un produit de qualité de faire réaliser cette indexation
de manière manuelle par des spécialistes du domaine. De plus le thesaurus étant
conçu avant tout pour l'indexation , il peut se prêter mal à la recherche à
partir du vocabulaire courant, ce qui en fait souvent un outil réservé à des
domaines spécialisés. La nécessité de maîtriser le langage avant la recherche,
l'absence de prise en compte de certaines relations associatives ou
d'équivalence peuvent entraîner du silence lors de l'interrogation. Le
silence est le fait qu’un système ne fournisse pas certains documents
pertinents pourtant contenus dans la base interrogée.
VI-4. Les méthodes linguistiques
IV-4.1 Introduction et comparaison par rapport aux méthodes
d’indexation précédentes
Nous avons vu que la technique d’indexation libre du
texte intégral privilégie l’exhaustivité par extraction et indexation de tous
les mots des textes (mis à part les mots vides). Des techniques statistiques
venaient ensuite effectuer des pondération sur ces mots pour établir un
classement par pertinence des documents au sein de l’index. Le rôle que c’est
fixé la linguistique automatique est d’améliorer cette pertinence en faisant
analyser des textes par des machines informatiques pour qu’elles en traitent le
contenu textuel et non pas uniquement les mots. Les traitements auront pour
tâche notamment de résoudre le problème de l’ambiguïté du langage aussi bien au
niveau de l’indexation que de la recherche.
On s’intéressera pour cela dans les premières phases à
une analyse morphologique des mots et à une analyse syntaxique de ces mots au
sein des phrases. Ces étapes d’analyses du texte en indexation permettront de
réduire le nombre et les types d’entrées d’index par rapport à un index en
texte intégral standard. Au niveau de la recherche elles permettront également
des interrogations plus riches comme par exemple une interrogation composée de
groupes nominaux et dans le cas le plus évolué des interrogations en langage
naturel (constitué de phrases complètes).
Il faudra cependant que les traitements linguistiques
soient effectués aussi bien au niveau de l’indexation qu’au niveau du texte de
la requête afin de faire correspondre les termes de la requête avec ceux de
l’index.
La dernière approche et nécessitant l’application des
analyses précédentes consiste à s’intéresser au sens des textes : c’est la
sémantique. On verra l’utilisation des ontologies à ce niveau qui consistent à
attribuer à un ensemble de mots un sens global qui s’apparente à des concepts.
Il est vrai que d’une certaine façon l’indexation par thésaurus prend en compte
la composante sémantique du langage mais d’une manière trop restrictive qui se
limite à un aspect « purement linguistique » de relations entre les
mots d’un texte. Les réseaux sémantiques (que l’on verra au paragraphe VI-2.1)
ont à peu près le même niveau d’usage que les thésaurus au niveau sémantique.
IV-4.2 Principes des techniques
linguistiques d’indexation
Les systèmes utilisant ce principe combinent
différentes analyses linguistiques pour le traitement du langage naturel. Ils
sont formés de plusieurs modules de traitement linguistique ayant chacun un
niveau d’analyse spécifique. Ces niveaux d’analyses peuvent aussi bien être
appliqués sur les textes à indexer que sur l’analyse du texte des requêtes.
Plusieurs moteurs de recherche et d’indexation
linguistiques sont présentés dans cette partie qui utilisent une ou plusieurs
techniques d’indexation. Ces outils tels que Intuition [13], Lexiquest[14],
Pertimm[15] n’ont pas besoin d’intervention
humaine pour réaliser leur indexation. Cependant il existe également des outils
qui proposent des méthodes semi-automatiques d’indexation. En annexe 5
on trouvera au sein d’une tentative de classification plusieurs outils qui
utilisent de la sémantique dans leur mode de recherche. Un moteur sémantique se
doit de réaliser au moins les trois premiers niveaux d’analyse parmi ceux qui
vont être présentés.
Les différents niveaux d’analyse linguistique sont les
suivant :
1) Le niveau
morphologique
On isole chaque terme par le biais d’un dictionnaire
qui permet le contrôle des chaînes de caractère et le repérage des mots. On
devra cependant prendre en compte le polymorphisme de mot appartenant à un même
concept, le traitement se traduit par la suppression des variantes
combinatoires (flexion, dérivation, conjugaison) pour obtenir une forme
canonique par réduction (appelé aussi lemmatisation). Les outils
nécessaires à ce procédé de réduction sont les dictionnaires de correspondances
entre formes fléchies ou dérivées et formes canoniques ainsi que des règles
d’établissement par correspondance. Par exemple produira, produisent, ont
produit etc., auront la même forme canonique produire (on dit aussi
que le terme produire est le lemme de ses formes fléchies produira,
produisent, ont produit).
Application en indexation (voir illustration document 15) : il existe des modes d’indexation libre par fichier
inverse de lemmes, obtenu par l’ensemble des opérations : découpage,
lemmatisation, élimination des mots vides, inversion. Il est également possible
de pondérer les index ainsi obtenus. On obtient en fait un index inversé de
mots comme dans la technique d’indexation en texte intégral (paragraphe IV-I).
Simplement par un traitement linguistique les mots qui pointent sur des
documents ont tous cette fois une forme lemmatisée
Dans ce cas au moment de l’interrogation, une
lemmatisation de la requête doit également être effectuée afin de faire
correspondre les termes de la requête avec ceux de l’index. Ce mode
d’indexation a un intérêt certain pour retrouver des concepts dans un texte,
même s’ils ont été exprimés dans la question sous une forme différente.
Par exemple si je réalise une recherche sur le terme
produire j’obtiendrait les documents contenant le terme produire mais
aussi les document contenant les formes fléchies de ce mot comme produisent,
produira, ont produit, etc. Dans le principe on réalise donc une expansion
de la requête. Le problème est que ce seul niveau d’analyse engendre des
ambiguïtés sémantiques.
Non seulement les formes fléchies peuvent correspondre
à plusieurs lemmes (le terme livres est soit le nom – féminin ou
masculin – au pluriel, soit le verbe conjugué à la deuxième personne du présent
de l’indicatif ou du subjonctif) mais un même lemme peut aussi être ambigu (présent
peut être associé au temps, à un cadeau, au fait d’être là).
Ainsi une analyse syntaxique complète des phrases doit être réalisée en
parallèle pour lever certains cas d’ambiguités.
Une indexation de ce type a été mise en œuvre dans les
logiciels suivants : AlethIP de LEXIQUEST[14](annexe 4),
Intuition de SINEQUA[13],
Pertimm de SYSTAL[15],
Spirit de TECHNOLOGIES-GID[11](annexe 4), Pericles de DATOPS [16], Exalead < http://www.exalead.com/>.
2)
L’analyse syntaxique :
L’analyse syntaxique part des phrases et consiste à
déterminer les regroupements structurels des mots au sein de ces phrases, ainsi
que les relations entre les mots, et les relations entre les structures de
mots. Elle cherche par exemple à obtenir des analyses de type sujet – verbe –
complément, ou plutôt groupe nominal sujet – groupe verbal – groupe
nominal complément. Dans la plupart des modèles syntaxiques, l’analyse
d’une phrase aboutit à une représentation hiérarchique ou arborescente, dans laquelle
les mots sont regroupés en unités intermédiaires ou syntagmes, qui
s’emboîtent les uns dans les autres. En sortie d’une analyse, on trouve ainsi
généralement un arbre syntaxique, avec des informations syntaxiques attachées
aux nœuds et aux extrémités des branche de cet arbre. L’exemple du document 16 montre
une phrase (simple) et son arbre syntaxique développé sur plusieurs niveaux.
Ainsi l’analyse syntaxique permet de résoudre quelques
cas d’ambiguïté en s’appuyant sur la structure grammaticale de la langue. Par
exemple dans la phrase « l’homme approcha une chaise de la table »,
le mot table ne peut être qu’un nom et pas la forme conjuguée du verbe tabler.
Application en indexation (voir illustration document 17). Certains systèmes utilisent un mode d’indexation libre par
fichier inverse de syntagmes ou mots composés. Sur ce type d’indexation, les
index peuvent être aussi pondérés par des critères statistiques. On trouve une
indexation de ce type dans Pertimm de SYSTAL[15], et Spirit de TECHNOLOGIES-GID[11]. Dans le logiciel Intuition de SINEQUA[13] et Pericles de DATOPS [16], on trouve un traitement
syntaxique plus poussé avec une indexation libre par syntagmes nominaux
étendus.
Par exemple les ellipses en particulier vont être
prises en compte ; par exemples, firmes publiques et privées
sera indexé par firmes publiques, firmes privées.
Un autre aspect est la normalisation de la catégorie
syntaxique des termes retenus : on n’indexera plus maintenant que par des
groupes nominaux. Cela conduit à nominaliser les verbes. Exemple : « La
visserie a été resserée » sera indexé par « resserrage de la
visserie »
L’indexation peut aussi être contrôlée à ce niveau en
utilisant des listes de termes autorisés pour déterminer parmi les groupes
nominaux reconnus ou générés ceux qui sont correct. Le risque est alors à
nouveau d’obtenir du silence en éliminant des termes présent dans le texte à
indexer mais non répertoriés dans la liste de référence.
3)
L’analyse
sémantique :
C’est l’analyse du sens du texte.
On distingue deux niveau d’analyse sémantique :
la sémantique lexicale et la sémantique du discours.
-
La sémantique
lexicale :
Elle s’appuie sur l’analyse du texte pour déterminer
les concepts qu’il contient ; elle privilégie donc l’analyse des mots et
des groupes de mots. Elle s’appuie sur les réseaux sémantiques par exemple. Un
réseau sémantique est un graphe formé de nœuds, qui représente des concepts,
reliés par des arcs orientés et étiquetés, qui représentent les relations
sémantiques entre ces concepts. Il est aussi appelé graphe de concepts. Nous
verrons des exemples de réseaux sémantiques et
des exemples d’utilisation dans le paragraphe VI-2.
-
La sémantique du
discours ou pragmatique :
L’analyse du discours est beaucoup plus ambitieuse et
tend à analyser le sens du texte complet, ce qui est très complexe. En effet,
dans un même texte, on peut trouver des phrases apparemment contradictoires, du
point de vue purement lexical.
Exemple de l’indexation contrôlée à l’aide
d’ontologies : Le principe est
d’utiliser des listes de catégories ou champs sémantiques appelés aussi ontologie.
La définition d’une ontologie est la suivante :
une ontologie est un catalogue sémantique, dont les descriptions sont à la fois
concises, non ambiguës, et qui se doit d’être exploitable par un logiciel
(description formelle) comme par un opérateur humain (description littéraire).
Les ontologies sont des structures hiérarchiques
censées représenter les choses du monde. Il y a deux approches différentes:
- Trouver une taxinomie des
concepts les plus généraux. Cette ontologie de niveau supérieur vise à
englober la totalité des concepts, sans pourtant entrer dans les détails
des concepts spécifiques.(Guarino, 1997) (document 18)
- Trouver une hiérarchie de
concepts d'un domaine limité, par exemple de la législation, de la
production de voitures, de la maladie de cancer... Cette ontologie de
domaine peut contenir des représentations de concepts spécifiques très
détaillées.
Il s’agit donc en fait d’unités de sens assez généraux
qui servent à regrouper des termes voisins plus spécialisés qui ont la même
signification ou dont le sens est proche. Par exemple sur le document 18 (page
précédente) ont constate que les termes homme, animal et plante
peuvent être rattaché à l’unité de sens être vivant.
Avant de rattacher des mots à une unité de sens un
certain nombre de regroupements préalables entre les mots doivent être
effectués :
-
Regroupements
morphologiques permettant de constituer des familles de mots regroupés autour
d’un représentant canonique, dont la seule fréquence d’apparition sera prise en
compte (produire, producteur, productrice, productif, productive sont
rattachés à production). Le niveau sémantique comprend donc les niveaux
d’analyse morphologique et syntaxique que l’on a vu précédemment.
-
Regroupements
synonymiques et analogiques permettant de ramener à une seule unité des formes
différentes mais liées entre elles par leur relation de sens (scanner=numériseur=digitaliseur ;
carcéral, prison, enfermement, etc.) ;
-
Regroupements
hyperonymiques permettant de regrouper sous un terme générique un ensemble de
termes spécifiques (machine à laver le linge, machine à laver la
vaisselle, fer à repasser, etc. sont regroupés sous le terme
générique électroménager).
Pour réaliser les deux derniers regroupement on pourra
s’aider éventuellement de thésaurus ou de réseaux sémantiques.
On obtiendra au final une liste de libellés de sens
qui constituera l’ontologie.
Pour exemple, le logiciel Intuition de la société
SINEQUA[13] utilise 770 champs sémantiques de
référence, dans lesquels les principaux mots et expression de la langue
française ont été classés.
L’utilisation d’une telle ressource en indexation est
la suivante (voir illustration document
19): les mots et termes qui sont extraits des documents sont
d’abord filtrés à l’aide d’une liste terminologique. Il est ensuite possible, à
partir d’une analyse statistique, de déterminer quels sont les concepts de
l’ontologie les plus représentatifs du texte, et d’utiliser le libellé de ces
concepts comme index. Il s’agit là d’indexation contrôlée qui atteint
véritablement le niveau sémantique.
Ce type d’indexation était potentiellement réalisable
par AlethIP de LEXIQUEST [14].
La principale difficulté de ce mode d’indexation tient
à l’attribution correcte des concepts ou champs sémantiques au texte, en
fonction de son contenu. Là encore, si certains concepts spécifiques d’un
domaine sont absents de la liste de référence, ils n’apparaîtront pas dans
l’index, et cela sera source de silence.
Ce type d’indexation présente le gros avantage de la
généralité et de l’indépendance de la représentation des textes par rapport au
vocabulaire utilisé : les index sont indépendants du vocabulaire, et c’est
véritablement les concepts, c’est à dire le niveau purement sémantique qui prime.
Cependant, ce qui est gagné en généralité est forcément perdu en précision.
IV-4.3 Deux niveaux d’utilisation des
techniques linguistiques
Nous passé en revue les différents traitements
linguistiques qui peuvent s’appliquer sur des documents textuels en vu de leur
indexation. La finalité de ces traitements étant d’améliorer la pertinence des
résultats en autorisant dans le cas le plus évolué une recherche en langage
naturel. La situation idéale est obtenu lorsque textes et questions sont
exprimés dans un même, référentiel, dont le caractère univoque autorise une mise
en correspondance exacte des index et des requêtes. Pour cela dans le cas
d’un mode de requête en langage naturel, les traitements linguistiques peuvent
intervenir non seulement au niveau de l’indexation mais aussi de l’analyse de
la question.
Ainsi deux types de solutions sont disponibles sur le
marché :
-la première solution privilégie l’analyse
linguistique au niveau de l’indexation :
- la deuxième solution privilégie l’analyse linguistique
au niveau de la recherche :
Cette dernière approche suppose que les documents
soient indexés en mode texte intégral sans analyse linguistique préalable. Dans
ce cas l’analyse de la question devra être plus importante que dans la solution
précédente pour poser la requête adéquate au moteur de recherche.
Voyons maintenant le fonctionnement général des ces
deux approches :
ØApproche privilégiant l’analyse linguistique au niveau
de l’indexation (document 20) :
L’indexation du texte est effectuée de manière
canonique, c’est-à-dire que les entrées d’index sont structurées avec le
dictionnaire électronique, ou, selon le cas, le réseau sémantique. Ensuite lors
de la recherche, le logiciel analyse la question posée de la même manière que
lors de l’indexation. Puis il normalise les termes de la question, parcourt le
dictionnaire ou le réseau sémantique – phase appelée d’expansion sémantique –
pour désambiguïser les termes et étendre la recherche. Il lance ensuite la
requête sur les index canoniques.
Le logiciel va donc composer une requête en ajoutant
des termes proches sémantiquement, éventuellement en les pondérant. Puis il va
générer une requête, par exemple booléenne à l’aide de ces critères pondérés.
Par exemple prenons la phrase : « La rencontre entre représentants
syndicaux et patronaux n’a pas abouti du fait des divergences de vue ». La
requête générée pourrait être la suivante : (‘Désaccord’ OU ‘divergence de vue’ .8 OU ‘refus’ .2)
ET (‘salarié’ OU ‘employé’ .75 OU ‘représentation des salariés’ .8 OU
‘représentant du personnel’ .8 OU ‘représentant syndical’ .8) ET (‘patron’ OU
‘chef d’entreprise’ .9 OU ‘représentant patronal’ .7) SAUF (‘Couture’) … Le résultat de la recherche est alors déterminé et
affiné le cas échéant en fonction d’une pondération des termes de la question.
ØApproche privilégiant l’analyse linguistique au niveau
de la recherche (document 21) :
Dans ce cas, l’outil linguistique est indépendant du
moteur d’indexation et de recherche. Le texte est indexé en texte intégral
classique. La question est analysée, normalisée, enrichie via le dictionnaire
électronique ou le réseau sémantique, puis une requête est générée qui combine
les termes possibles reflétant les concepts identifiés dans la question. La
requête posée au moteur de recherche comporte alors de très nombreux termes.
L’exemple d’Altavista : La technique d’indexation du moteur de recherche
Altavista est le texte intégral.Cependant Lexiquest et AltaVista ont signé un
partenariat pour intégrer les outils de traitement du langage à la plate-forme
logicielle AltaVista Search Engine 3.0 pour améliorer le fonctionnement des
applications de gestion des connaissances [22].
AltaVista Search Engine 3.0 est la version intranet du moteur de recherche
Altavista. Les questions posées en langage naturel via AltaVista Search Engine
3.0 seront étendues, améliorées et traduites par le logiciel LexiGuide en
requêtes booléennes sophistiquées reconnues par AltaVista.
IV-4.4 Comparaison de l’approche privilégiant l’analyse linguistique au niveau de l’indexation et de l’approche privilégiant l’analyse linguistique au niveau de la recherche
L’un des points essentiels du fonctionnement de la
recherche en langue naturelle est le contenu des index : mots du texte,
formes canoniques des termes, ou concepts (nœuds du réseau sémantique avec une
représentation interne). Si tous les mots du texte sont stockés dans l’index
sans analyse linguistique préalable (comme dans le deuxième cas avec une
indexation en texte intégral), la question posée va être très largement
étendue, d’autant plus que la composante sémantique est prise en compte. A
contrario, l’indexation sera effectuée de manière très rapide car sans
traitement préalable. Si les formes canoniques des mots et expressions sont
stockés dans l’index comme c’est le cas dans la première approche, l’expansion
de la requête sera moindre, mais l’indexation nécessitera davantage de
traitement. Si les concepts sont stockés dans l’index, ce sera la question qui
sera en fait simplifiée.
Pour résumer nous dirons que le travail qui n’est pas
fait au moment de l’indexation doit être réalisé ensuite lors de
l’interrogation. Cela coûte plus cher à tous les points de vu. Une loi, connue
depuis longtemps en sciences de l’information [9], s’exprime comme suit : tout travail de
classement et de référencement non réalisé en amont, au moment de la réception
de l’information, se traduit ensuite en aval, au moment de la recherche, par
une dépense d’énergie, un temps et un coût, supérieurs de plusieurs ordre de
grandeur. L’illustration de cette loi dans un contexte de documentation
papier est évidente : recevoir un document, le lire en diagonale et le
classer dans un emplacement adéquat, prend quelques instants. Si cela n’est pas
fait, retrouver ensuite ce document, non rangé, au milieu d’un monceau de
papiers en vrac, prendra des heures, voire sera impossible. C’est exactement
pareil avec l’information électronique : les difficultés de recherche sur
le Web en sont l’illustration éloquente.
Cependant le problème sur le Web est la quantité de
documents à indexer sans cesse grandissante ainsi que leurs très grande
hétérogénéité. L’usage d’une indexation prenant en compte la morphologie et la
syntaxe des mots peut être applicable. Cependant l’application d’une technique
d’indexation basé sur de la sémantique est difficilement réalisable et dans ce
contexte c’est l’indexation en texte intégral qui prime. Par exemple, il est
vrai que l’utilisation d’ontologie pour l’indexation se révèle efficace sur des
corpus de documents qui ont un vocabulaire contrôlé par exemple dans un domaine
spécialisé. Cependant l’application d’un tel type d’indexation au contenu du
web risque de ne pas s’avérer pertinente au niveau des résultats de recherche,
du fait de la très grande hétérogénéité du type de vocabulaire utilisé. En
effet en dehors du multilinguisme, au sein d’une même langue de nombreuses
variations existent : vocabulaire courant, vocabulaire spécialisé, etc.
C’est l’un des enjeux du web sémantique que de
vouloir attribuer un sens à tous les documents d’Internet, mais son application
se révèle très difficile.
Au contraire, dans un contexte restreint comme un
intranet et appliqué à un corpus de documents spécialisés, l’utilisation de
l’analyse sémantique pour l’indexation peut se révéler efficace. Pour exemple
Leroy Merlin a opté pour le logiciel Intuition qui comprend un dictionnaire
spécialisé dans le bricolage. Intuition devient alors un moteur de recherche spécialisé.
A la requête hérisson, l'utilisateur final n'aura ainsi pas de
renseignements sur le mammifère insectivore, mais sur l'outil de ramonage.
L’avenir du web sémantique se situe plus dans des outils d’aide à la
reformulation de la requête pour limiter les cas d’ambiguïté. Concrètement, sur
le web, par rapport à cette même requête sur hérisson, l’outil devra
être capable de demander à l’utilisateur si le terme hérisson se réfère
à l’outil ou à l’animal. La requête sera alors étendue et les documents rapatriés
plus ciblés.
V-1. Le mode requête en langage booléen
Ø Les opérateurs booléens
Leur nom
est tiré de celui de George Boole (1815-1864), mathématicien anglais,
auteur de la théorie des ensembles. La recherche booléenne repose sur les trois
opérations suivantes :
|
Opération |
Opérateurs
|
équivalents en anglais |
|
Union |
OU |
OR, all of the
terms, CAN CONTAIN |
|
Intersection |
ET |
AND, any of the
terms, MUST CONTAIN |
|
Exclusion |
SAUF |
NOT, NOT AND,
MUST NOT CONTAIN |
L'union permet de rechercher sur des concepts proches,
des synonymes ce qui est important pour des questions posées en vocabulaire
libre. L'intersection impose la présence de tous les critères de recherche.
Ø La syntaxe (presque
commune)
La plupart des outils de
recherche utilise la syntaxe suivante qui pourra être employée sans risque
grave :
|
Opération |
Opérateurs
|
exemple |
|
Rechercher une expression |
"" |
"vache folle" |
|
Imposer un terme |
+ |
+vache +folle |
|
Exclure un terme |
- |
+bretagne -grande |
|
Tronquer un terme |
* |
vache* |
Attention,
les signes + et - doivent être collés à gauche du terme concerné. Cette syntaxe
correspond en général aux formulaires de recherche simple.
Remarque : D'un outil de recherche à l'autre existent des
différences de traitement :
o
les mots vides peuvent
être filtrés ou non ;
o
l'opérateur implicite
est soit le ET soit le OU;
o
l'ordre des mots de la
question peut avoir une importance dans le tri des résultats ;
o
les majuscules et les
minuscules peuvent être différenciées ou non ;
o
les lettres accentuées
sont souvent mal gérées sur les outils anglo-saxons.
ØLes opérateurs de proximité
Dès que
l'on recherche dans des documents en texte intégral, l'opérateur ET est
insuffisant. Les opérateurs de proximité ou d'adjacence permettent de préciser
la position de deux termes l'un par rapport à l'autre. On trouve les opérateurs
suivants :
|
Opérateurs |
Explications |
|
NEAR |
les 2 termes sont proches, l'ordre n'est
pas pris en compte |
|
NEAR/n |
n indique le nombre maximum de mots
admis entre les 2 termes |
|
FOLLOWED BY |
l'ordre des termes est pris en compte |
Peu
d'outils utilisent les opérateurs de proximité : Altavista, Lycos. Google
ne l’utilisent pas. Dans le cas de l’opérateur NEAR les deux mots-clés sont
proches de dix mots ou moins (c’est une garantie de relation entre eux). Par
exemple : hanche NEAR fracture, fournit les fractures de la hanche. Sur
certains moteurs la distance maximum entre les mots est de 50 au lieu de 10. Un
autre opérateur est l’opérateur d’adjacence ADJ : les deux
mots-clés sont à deux mots ou moins, l’un de l’autre ;
Ø L'utilisation
des parenthèses
L'utilisation des parenthèses est permise
uniquement dans le mode avancé.
Les mots employés entre parenthèses seront
évalués en premier.
Ex.: pollution AND (lac OR lacs OR
rivière*)
ØLa recherche
par zone
La recherche dans certaines zones est possible. Il
suffit d'inscrire le nom de la zone suivi de l'expression recherchée. Nom des
zones recherchables : title,
url, host, link, etc.
Ex.: title:bibliothèque and url:cmontmorency (pages dont le titre contient le mot bibliothèque et dont
l'adresse URL contient cmontmorency.)
ØLa troncature
Les moteurs
de recherche tronquent souvent les termes sans prévenir. Cela peut produire du
bruit.
C'est l'étoile * qui est en général utilisée. Celle-ci remplace une chaîne de
caractères manquant (informati*=information, informatique, etc.). A l’inverse
l’utilisation d’un point d’interrogation peut servir à remplacer un caractère
manquant (psycholog?e=psychologue, psychologie). Attention car la troncature
peut être implicite, explicite ou absente, ce qui peut produire du bruit.
Certains outils francophones proposent une recherche tenant compte de règles
grammaticales et d'exceptions pour élargir la recherche.
ØLe mode recherche avancé
La recherche web avancée permet de créer des requêtes spécifiques indiquant à un moteur de recherche de retourner des résultats plus précis. Dans le cas des moteurs de recherche sur Internet cela correspond à une interface qui reprend le plus souvent, pour la majeur partie des fonctionnalités, l’équivalent de ce qu’il est possible d’obtenir avec les opérateurs booléens. Simplement la forme est plus conviviale et ne nécessite pas de connaître la syntaxe. Dans le document 23 on peut voir le mode requête avancé de Google et en annexe 7 pour vous permettre de comparer les fonctionnalités l’interface en mode recherche avancé d’Altavista.
ØRecherche floue
Pouvant
être branché ou non au moment de l’indexation, le module de recherche floue
permet d’étendre la recherche. Il s’applique aux mots inconnus de la requête
pour lesquels il est possible de trouver, dans la base, des mots proches (noms
communs ou noms propres), à un ou plusieurs caractères près.
ØLa technique d’expansion de requête
Une
nouvelle méthode utilisée aujourd’hui dans les logiciels de recherche
d’informations pour limiter le silence, est l’expansion de requête à l’aide
d’un thésaurus, d’une terminologie structurée ou d’un réseau sémantique. Cela consiste
à prendre les termes de la requête initiale, à leur associer des termes voisins
définis par un référentiel terminologique (en utilisant des liens comme
synonymie, association, etc), et à générer une requête plus large, comprenant
l’ensemble des termes initiaux et des termes associés.
ØLa recherche par question
Certains services disponibles sur Internet utilisent un interpréteur de langage simple pour répondre aux questions des utilisateurs par un site spécifique. Ces moteurs sont une solution hybride qui se distingue des vrais moteurs en langage naturel. Ils se content d’associer la requête à une question déjà formulée en fonction des mots-clés et pour laquelle ils ont une solution. Ils sont néanmoins incapable de gérer immédiatement toute question imprévue.
Exemple : Ask Jeeves < http://www.ask.com/ >: ce moteur va
automatiquement chercher dans une base de données de questions préalablement
définies celles qui se rapprochent le plus de celle posée. Pour chacune de ces
interrogations « type », une réponse a déjà été trouvée sous la forme
d’un site précis ou d’une page donnée. Les questions les plus approchantes sont
donc affichées et, pour chacune, la réponse adéquate proposée.
Dans certains systèmes existe un mode de recherche par l’exemple, ou par similarité, appelé en anglais Query by Example – QBE en abrégé – ou Find similar : lorsque l’utilisateur possède un document qui correspond exactement à sa problématique ou à son centre d’intérêt (d’emblée ou suite à une première requête), il utilise tout ou une partie de ce document comme nouvelle requête. Le logiciel utilise l’ensemble des termes présents dans le texte sélectionné, ou ceux qui sont jugés les plus significatifs. Il extrait parmi les réponses, celles qui sont proches du texte de référence, donc de la question initiale au sens de l’utilisateur. Le QBE joue donc un double rôle d’expansion de requête et de filtrage.Quatre moteurs de recherche utilisent cette fonction : AltaVista, Excite Canada et Excite France, Go et Google.
ØLa recherche par le sens des mots
En annexe 5 est
présenté une tentative de catégorisation des moteurs de recherches. Parmi cette
classification on trouve les moteurs de recherche sémantiques avec parmi eux le
logiciel Intuition décrit ci-dessous mais aussi d’autres moteurs. En annexe 6 des
références sur les sites ou ces moteurs sont utilisés permettent d’aller tester
en ligne la solution des éditeurs.
L’exemple
du logiciel Intuition de Sinequa
L’originalité
avec ce logiciel est que l’utilisateur a la possibilité d’effectuer une
recherche principalement par les mots ou par les sens, exclusivement
par les mots ou par le sens, ou par les deux de façon équivalente. Il
est possible de régler ce paramètre en fonction du niveau de précision souhaité
dans le choix des réponses.
1.
Une recherche par
les mots.
Elle permet de rechercher dans la base tous les
documents contenant le plus grand nombre possible de mots de la requête. Une
analyse syntaxique permet de distinguer les mots grammaticaux des noms, verbes
ou adjectifs homographes (or, car), et de retrouver la bonne forme de base en
cas de doute (pêche, avions). Chaque mot peut alors être retrouvé sous l'ensemble
de ses formes fléchies.
La recherche par les mots peut également s'accompagner
d'une recherche floue à un ou plusieurs caractères près, et/ou d'une recherche
sur ses synonymes. Au moyen d'une syntaxe particulière, on peut exiger la
présence d'un mot dans les documents réponses ou au contraire l'en exclure.
Un traitement particulier est réservé aux acronymes et
aux sigles, qui pourront être retrouvés avec ou sans les points séparateurs
(Unesco, U.N.E.S.C.O.). La casse peut-être respectée ou non, de même que
l'emploi des caractères accentués. Des mots peuvent être souhaités adjacents
dans les textes (aux mots grammaticaux près) ou présents dans un même groupe
nominal.
2. Une
recherche par le sens.
Très différente de la recherche précédente par les
mots, celle-ci ne s'emploie pas à retrouver séparément dans un document les
éléments de la requête. Au contraire, elle va modéliser, au moyen d’un modèle
vectoriel et sémantique, le sens global de la requête, et le rapprocher du sens
global de chaque document de la base. On entend ici par "sens
global", une image de l'ensemble des thèmes et sujets abordés dans le
document, pondérés par leur fréquence d'apparition.
Dans le modèle vectoriel [Salton et al. , 1975], un texte est représenté par un vecteur dans un espace
à 800 coordonnées. Différents traitements sont appliqués sur ce vecteur afin de
prendre en compte l'analyse contextuelle. Reste ensuite à calculer la distance
entre le vecteur-question et les vecteurs-document, de façon à retrouver les
documents dont le contenu sémantique s'approche le plus possible de celui de la
requête.
Ø Un mode de recherche prenant en compte la connotation
du discours et autorisant une recherche sur des groupes nominaux
L’exemple des produits de la société Datops [16]
L'originalité
du système est de pouvoir reconnaître des phrases négatives en prenant en
compte la mesure de la tonalité. La mesure de la tonalité s’apparente à la
sémantique. C’est en fait la mesure de la connotation du discours comme par
exemple savoir si ce discours parle positivement ou négativement d’une
personne, d’une société, etc. Cela se traduit par des coefficients de tonalité
qui viennent pondérer les mots qui servent à indexer les documents. L’analyse
de la tonalité se fait à l’aide de lexique de mots auxquels sont associé un
indice de tonalité. Le système peut également réaliser des graphes de
connotations à partir de cette analyse (voir les exemples de graphe en annexe 10)
Les
produits de la société Datops proposent également deux autres types
d’interrogation :
-
une interrogation par
mot-clé sur des index inversés de lemmes
-
une interrogation par
groupes nominaux sur des index inversés de syntagmes nominaux
La
technologie linguistique se met également en place au niveau de la collecte des
documents par analyse morpho lexicale et synthaxique. Elle joue ainsi un rôle
de filtrage des pages collectées en diminuant le bruit ce qui en fait un outil
bien adapté à la veille(voir document 24).
C’est
donc un outil de recherche automatique (voir paragraphe III-2).
Pour
cela une série de premiers index de lemmes et de syntagmes est construite sur
la base de l’ensemble des documents collectés (voir document 24 page
précédente) autour d’une thématique assez générale comme par exemple l’alimentation.
Le logiciel interroge ensuite automatiquement cette ressource à partir de la
requête paramétrée par un gestionnaire à l’avance. Cette requête plus précise
sur le thème traité peut demander par exemple de récolter tous les documents
traitant des futures crises alimentaires. Une deuxième série d’index de
lemmes et de syntagmes est ainsi construite à partir du résultat de cette
interrogation. C’est sur cette deuxième série d’index que l’utilisateur pourra
interroger les documents collectés.
Le document en annexe 9 est
un extrait d'une réponse faite à un questionnaire technologique dans le cadre
d'un appel d'offre pour la société Datops et qui m'a été fourni par Olivier
Massiot qui travaille pour le secteur R&D de cette société. Ce document
illustre bien les choix technologiques utilisés pour les produits Pericles,
InfoMonito, RiskMetrics mais aussi les alternatives qui peuvent être utilisées
dans les domaine de la recherche d'informations à l'aide des traitements et
analyses linguistiques
Ø Le mode recherche en langage naturel
L’exemple de Verity (document 25):
Grâce aux dictionnaires, aux règles de découpage, aux
règles de lemmatisation et aux réseaux de concepts, le logiciel VERITY[12] ajoute la recherche sémantique à
la recherche en texte intégral. Cette synergie apporte un taux de pertinence
élevé. Les utilisateurs peuvent ainsi formuler leur recherche en langage
naturel. VERITY met ces fonctionnalités à disposition pour un grand nombre de
langues.
Nous
verrons dans ce chapitre les différentes technologies utilisés par les moteurs
pour effectuer automatiquement le classement des documents rapatriés à partir
d’une requête d’un utilisateur. Nous verrons également les outils aidant
l’utilisateur à raffiner les résultats obtenus.
VI-1. Les méthodes de tri utilisées
La masse
d'informations disponibles renvoyé par les moteurs de recherche est la plupart
du temps trop importante, ce qui déroute les utilisateurs. Aussi les moteurs de
recherche ont développé des méthodes de tri automatiques des résultats .
Dans la pratique
aucune méthode de tri n'est parfaite mais la variété de ces méthodes offre à
l'utilisateur la possibilité de traquer l'information de différentes manières
et augmente donc ses chances d'améliorer ses recherches. Le but du classement
est d'afficher dans les 10 à 20 premières réponses les documents répondant le
mieux à la question. Si on ne trouve pas ce que l'on cherche dans les toutes
premières pages de résultats, il faut reformuler la question. Comprendre les
mécanismes de classement des moteurs de recherche permet vraiment d’en tirer
profit.
VI-1.1
Le tri par pertinence
Cette méthode repose sur
des travaux de recherche déjà anciens de Robertson et Sparckjones [24], mis en pratique dans le logiciel
d'indexation WAIS [23]
à la fin des années 80. Les résultats d'une requête sont affichés selon un
ordre déterminé par le calcul d'un score pour chaque réponse. La pertinence est
basée sur les cinq facteurs suivants appliqués aux termes de la question :
1) Le poids
d'un mot dans un document est déterminé par sa place dans le document : il est
maximum pour le titre et le début du texte; à l'intérieur il est plus important
si le mot est en majuscule.
2) La densité
est basée sur la fréquence d'occurrence dans un document par rapport à la
taille du document. Si deux documents contiennent le même nombre d'occurrences,
le document le plus petit sera favorisé.
3) Le poids d'un mot dans la base est basé sur la fréquence
d'occurrence pour toute la base de données. Les mots peu fréquents dans le
corpus sont favorisés. Les mots vides sont soit éliminés, soit sous-évalués.
4) La correspondance d'expression est basée sur la
similarité entre l'expression de la question et l'expression correspondante
dans un document. Un document contenant une expression identique à celle de la
question reçoit le poids le plus élevé.
5) La relation de proximité est basée sur la proximité
des termes de la question entre eux dans le document. Les termes proches sont
favorisés.
Cette technique a montré
son efficacité dans le cadre des bases de données WAIS assez homogènes et peu
volumineuses. Elle a été reprise dans les moteurs de recherche apparus à partir
de 1994 et basés sur les techniques d'exploration du web par les robots .
Cependant l'algorithme exact n'est jamais connu car il est considéré comme
secret industriel et quelquefois protégé par un brevet (cas d'Excite). Les
documents HTML peuvent contenir dans l'entête des informations concernant le
contenu du document (voir paragraphe I-2). Ces méta-données
correspondent aux balises TITLE, META keywords et META description (voir
paragraphe I-2-2). Une étude a montré qu'elles étaient malheureusement peu
utilisées. Certains moteurs de recherche en tiennent compte dans leur
calcul.Cependant le tri par pertinence présente l'inconvénient d'être facile à
détourner par des auteurs désireux de placer leurs pages en tête de liste :
pour cela il suffit de répéter les mots importants soit dans l'entête, soit
dans le texte en utilisant des techniques de spamming ( écrire le texte en
blanc sur fond blanc par exemple) pour modifier à son avantage le classement.
Les moteurs ont réagi en détectant ses techniques.
Cette méthode est utilisée
par AltaVista, Ecila, Excite, FAST, HotBot, Inktomi, Lokace, Voila. Le résultat
dépend beaucoup de la question et l'on choisira, chaque fois que cela est
possible, des termes précis et non ambigus.
VI-1.2
Tri par popularité
Les limites du tri par
pertinence ont conduit à rechercher d'autres méthodes reposant sur des
principes tout à fait différents et indépendants du contenu des documents.
Connues sous le nom de tri par popularité, on distingue :
ØLa méthode
basée sur la co-citation
Lancé en 1998 par deux
étudiants de l'Université de Stanford, Google, classe les documents grâce à la
combinaison de plusieurs facteurs dont le principal PageRank [25] . Ce dernier utilise le nombre de liens pointant sur
les pages. Plusieurs moteurs de recherche offrent cette fonctionnalité. Avec
AltaVista il faut entrer : www.site.com -host:www.site.com. Cela
permet à n'importe quel auteur de pages de découvrir les liens pointant sur son
œuvre. Google évalue l'importance d'une page par les liens qu'elle reçoit mais
analyse en plus la page qui contient le lien. Les liens des pages
"importantes" pèsent plus lourdement et aident à découvrir d'autres
pages "importantes". Ainsi le tri est indépendant du contenu et évite
les dérapages de la méthode précédente, le choix des liens étant laissé à la
libre décision des millions d'auteurs de pages HTML. Il faut cependant noter
que cette technique défavorise les pages récentes et donc inconnues.
ØLa méthode
basée sur la mesure d'audience
La société DirectHit a été
fondée en avril 98 et propose de trier les pages en fonction du nombre de
visites qu'elles reçoivent. Sa technologie a été intégré depuis peu dans le
moteur de recherche Teoma. DirectHit analyse le comportement d'un internaute
dans l'utilisation d'un moteur de recherche. Le comportement des internautes
est généralement le suivant : Sur la page d'accueil, il saisit un ou
plusieurs mots de recherche dans un formulaire, consulte la page de résultats
classés par ordre de pertinence, choisit l'un d'entre eux, va sur le site correspondant
pour le consulter. Si la page ne lui convient pas, il revient sur la page de
résultats du moteur, choisit un autre lien, etc. jusqu'à ce qu'il ait trouvé un
document pertinent.
DirectHit enregistre
ce comportement pour tenter de trouver les pages les plus
"populaires" sur un moteur de recherche et ainsi améliorer leur
classement. Il fonctionne, en règle générale, en tâche de fond sur un moteur
existant. A chaque consultation d'un utilisateur, DirectHit note sur quel lien
celui-ci a cliqué et quel était le rang de ce lien. Il mesure le temps passé
sur une page avant que l'utilisateur ne revienne aux résultats. S'il ne revient
pas, il en "déduit" que le site proposé était pertinent. Il sera
alors mieux classé dans les résultats suivants, lors d'une interrogation sur le
même mot-clé. Ainsi les interrogations et la façon d'interroger et de naviguer
des internautes vont enrichir la base données de DirectHit. Cette méthode comme
la précédente pénalise les pages récentes mais évite le spamming. DirectHit
peut être interrogé directement sur son site mais alimente aussi les résultats
de nombreux outils de recherche comme HotBot, LookSmart et des sites Web comme
celui de ZDNet <. http://www.zdnet.com/
>
NorthernLight, lancé
en Août 1997, propose le classement des documents trouvés dans des dossiers
(clustering) constitués automatiquement en fonction des réponses. Un dossier
peut lui-même être constitué de sous-dossiers (document 26).
Il existe quatre types de sous-dossiers :
·
Subject (e.g., hypertension, baseball, camping, expert systems,
desserts)
·
Type (e.g., press releases, product reviews, resumes, recipes)
·
Source (e.g. commercial
Web sites, personal pages, magazines, encyclopedias, databases)
·
Language (e.g., English, German, French, Spanish)
Pour classer automatiquement des documents, il existe plusieurs
méthodes :
1) Méthodes basées
sur un calcul de similarité entre les documents (k-means analysis, hierarchical
-clustering, nearest-neighbor clustering) :
Chaque document est
représenté par un vecteur de mots (sélectionnés parmi l’ensemble des mots qui
apparaissent dans les documents) et on définit une mesure de leur similarité.
Les vecteurs associés à chaque document utilisent des techniques pour affecter
à chaque mot un poids qui dépend de sa fréquence dans le document et
dans la collection de documents (voir les formules çi-dessous). On normalise en
plus le poids suivant la longueur du document. Pour appliquer ces méthodes à la
classification de documents, il est impératif de réduire le nombre de termes
utilisés pour représenter chaque document (limiter la taille des vecteurs). Les
méthodes courantes de sélection de mots pour réduire ce nombre se basent sur
des critères de fréquence. Les mots les plus fréquents sont gardés et les
autres sont éliminés. Attention : cette méthode est bien sûr imparfaite
car un mot peut fréquent pourrait bien être important pour représenter une
catégorie.
Plusieurs formules pour calculer le poids du
terme t dans un document i ont été proposées :
|
Term
Frequency (TF) : l’importance d’un terme t est proportionnelle à sa
fréquence dans un document |
|
Inverse Document Frequency : les termes qui
apparaissent dans peu de documents sont intéressants IDF est censé améliorer la précision |
Mais Salton [26] a montré que les meilleurs
résultats étaient obtenus en multipliant TF et IDF :
|
TDIDF(t,i) =
TF(i,t) * IDF(t) |
|
TDIDF = (frequence(m, d) * log(N/n)) / Racine (
Somme sur termes t(tf²(t,d) * log²(N/t))) |
Remarque : Le modèle vectoriel de Salton propose de représenter
chaque document par un vecteur. Soit N le nombre total de termes distincts dans
la collection (appelé encore le vocabulaire), on représente chaque document par
un vecteur de N éléments. Bien sûr, N est généralement très supérieur au nombre
réel des mots présents dans un document. Il en découle que le vecteur contient
beaucoup de 0. Pour gagner en place, on représente un document par la liste des
termes qu’il contient, avec l’indice du terme. Si le document contient les
termes numéro 25, 500 et 768, avec des fréquences respectives de 5,10 et 7, on
associera au document la liste de couples (indice,fréquence) suivante : (25,5)
(500,10) (768,7).
On doit ensuite choisir une fonction de Distance (ou au contraire de Similarité) qui permet de comparer les documents deux à deux. Voici quelques exemples couramment utilisés et extraits de la littérature en recherche d’information :
|
Simple(i,j) = |Intersection(i,j) où Intersection =
les mots communs aux documents i et j |
|
Dice(i,j) =
|Intersection(i,j)| / (|i| + |j|) |
Une fois la
matrice de similarité calculée, il est possible de classer automatiquement les
documents. Comme annoncé, plusieurs techniques existent. Certaines sont dites
hiérarchiques (HAC) car elles produisent une hiérarchie, alors que d’autres
sont dites non hiérarchiques (single-pass, SOM). D’autres encore produisent des
classes floues (STC et Bayesian).
Citons pour exemple les méthodes
suivante :
K-mean [Rocchio 66]
On doit définir à l’avance
le nombre de clusters à obtenir. On répartit ces clusters en les représentant
par un vecteur, comme les documents à classer. Ensuite, on ajoute à chaque
cluster le document qui lui est proche. On recalcule le vecteur de ce cluster
(moyenne entre le vecteur du cluster et du nouveau document rajouté). On
continue ce processus tant qu’il reste des documents à classer. L’avantage est
qu’un document peut être rangé dans plusieurs clusters. L’inconvénient de cette
méthode est qu’on doit spécifier à l’avance le nombre de clusters. De plus, le
choix des clusters de départ semble important. Par contre, cette méthode est
rapide.
Cette méthode ne
produit donc pas de hiérarchies. Or la plupart des méthodes de classification
de documents sont au contraire des méthodes dites “ hierarchical
agglomerative clustering ” (HAC). En effet, la méthode K-mean ne peut
regrouper qu’un cluster et un document, et non pas un cluster et un autre
cluster.
Hierarchical
Agglomerative Clustering [Voorhees 86]
Le principe
de cette méthode est le suivant : on range au départ chaque document dans un
cluster. Ensuite on cherche les deux clusters les plus proches. On les fusionne
pour former un nouveau cluster et on répète tant qu’il reste au moins deux
clusters. Il existe plusieurs versions de cette méthode standard HAC (single
linkage, group average linkage, complete linkage). Seul le calcul de la
similarité entre deux clusters change :
-
pour single linkage,
Similarité = Similarité maximum entre un document de cluster1 et un document de
cluster2.
-
pour group average linkage, Similarité =
moyenne des similarités entre les documents de cluster1 et cluster2.
-
pour
complete linkage, Similarité = Similarité Minimum entre un document de cluster1
et de cluster2
On peut aussi diviser la valeur de la similarité par le nombre de documents présents dans le cluster : cela évite de produire des clusters contenant trop de documents.
Remarque : Notons que ces méthodes sont également très utilisées dans d’autres domaines comme la biologie pour effectuer des clusters de gènes qui sont co-exprimés (ayant un même profil d’expression).
Single-Pass [hill 68] : Une première méthode traite les documents
séquentiellement : on met le premier document dans un cluster. On regarde sa
similarité avec le second document. Si elle est supérieure à un seuil fixé par
l’usager, alors on range le second document dans le cluster (qui ne contenait
que le premier document). On continue avec le troisième document, et ainsi de
suite tant que la similarité entre le cluster défini et le document actuel
dépasse le seuil. La similarité entre le cluster et un document est la moyenne
des similarité entre chaque document du cluster et le document. Quand le seuil
n’est pas dépassé, alors on obtient un cluster et une liste de documents non
traités. On recommence au début en définissant un nouveau cluster qui contient
le premier document de la liste de documents non traités.
Buckshot anf Fractionation [Cutting 92] : Buckshot est une version modifiée
de k-means.
Suffix Tree Clustering
(STC) [Zamir 98] : Par rapport aux
méthodes précédentes, STC ne cherche pas à ranger chaque document dans un
groupe précis. Au contraire, un document peut appartenir à plusieurs groupes
(comme Autoclass). Contrairement aux autres approches, STC ne représente pas un
document par la liste non ordonnée des mots qu’il contient. STC s’intéresse aux
phrases communes aux documents.
Méthodes
probabilistes (Bayesian classification mise en oeuvre dans Autoclass) : elles font l’hypothèse de l’indépendance des mots, ce
qui est rarement le cas pour des documents, et elles nécessitent aussi de
réduire considérablement le nombre de mots utilisés pour les calculs.
Méthodes
basée sur les réseaux de neuronne (Self Organizing Maps) de Kohonen .
Ensuite, le résultat (la classification produite) est différent selon les méthodes :
-
les documents sont
séparés en groupe distincts
-
les documents sont
hiérarchisés
-
les documents
appartiennent à une et une seule classe
-
les documents peuvent
appartenir à plusieurs classes
VI-2. Les outils d’affinage des résultats
Un certain
nombre d’outils va aider l’utilisateur à reformuler ses requêtes pour améliorer
la pertinence des documents déjà rapatriés. Pour les moteurs où l’indexation est contrôlée par un
thésaurus nous avons décrit des outils graphiques permettant de guider
l’utilisateur pour le choix de descripteurs utilisés pour la recherche (paragraphe
IV-3). Nous allons présenter maintenant des exemples d’utilisation des
réseaux sémantiques pour l’aide à la reformulation des requêtes par les
utilisateurs.
Cependant il existe d’autres méthodes pour
aider l’utilisateur à reformuler ces requêtes et qui ne passe pas
nécessairement par l’utilisation d’interfaces. Le moteur Google par exemple
propose d’afficher en ligne
des conseils pour reformuler une requête. Il utilise notamment un correcteur
orthographique (document 27).
VI-2.1 L’utilisation des réseaux sémantiques
ØExemple du réseau sémantique spécialisé du projet Unified
Medical Langage System (UMLS) (document 28 page suivante) :
Le projet Unified Medical Langage System (UMLS) \index
UMLS [7] développé par la National Library of
Medicine (USA) se propose de fournir un outil permettant d’établir un lien
conceptuel entre le besoin d’une information exprimée par un utilisateur et
différentes sources d’informations informatisées comme des bases de données sur
la littérature médicale, les dossiers médicaux ou les bases de connaissances.
Dans cet outil un méta thésaurus contient des
informations sur les concepts médicaux qui sont tous affectés à une catégorie
sémantique ainsi que leur expression dans différentes classifications.
On y trouve également comment ces concepts ont été
utilisés dans les bases de données sélectionnées (MEDLINE, PDQ, DXPLAIN...).
MEDLINE PDQ DXPLAIN Il contient actuellement 66000 concepts et 100000 termes
environ. Le réseau sémantique représente uniquement les relations existant
entre les catégories sémantiques. Par exemple "virus" PEUT-CAUSER
"Maladie ou Syndrome". On peut parler dans ce cas d’ontologie .
Une ontologie est un catalogue sémantique, dont les descriptions sont à la fois
concises, non ambiguës, et qui se doit d'être exploitable par un logiciel
(description formelle) comme par un opérateur humain (description littéraire).
Le projet ARIANE [8]
vise à développer un moteur de recherche dans le domaine biomédical basé sur des documents médicaux indexé à
l’aide du meta-thésaurus de l’UMLS. L’exemple suivant illustre l’intérêt du
couplage du réseau sémantique au thésaurus : imaginons un utilisateur qui
manifeste à la fois son intérêt pour le concept ulcère gastrique et ranitidine.
L'interface conceptuelle d'ARIANE pourra proposer à l’utilisateur une liste de
relations existant entre ces deux concepts à partir du réseau sémantique de
l’UMLS. C'est ce que présente l'écran du document 29 page
précédente. A chacune de ces relations correspondra une liste de
documents en rapport. Par exemple si l’on choisi la relation traite, ce sera une liste de documents médicaux où les ulcères gastrique
seront traités à l’aide de la ranitidine.
ØExemple de réseau sémantique dans le cas du
vocabulaire courant :
Nous avons illustré le cas de l’utilisation d’un
réseau sémantique dans un contexte spécialisé. Cependant de nombreux chercheurs
se sont penchés sur le problème de la modélisation d’ensemble du vocabulaire
courant, d’un point de vue sémantique, qui est une tâche indispensable pour
développer des méthodes automatiques d’analyse et de recherche des informations
textuelles. Parmi ces travaux, le modèle WordNet, développé depuis 1985 à
l’Université de Princeton, au Cognitive Science Laboratory (laboratoire des
sciences cognitives), mérite d’être signalé. Il s’agit d’un réseau sémantique
général de l’ensemble du vocabulaire anglais d’usage courant, organisé sur la
base de concepts psycholinguistiques précis. L’unité de base dans WordNet est
le couple {unité linguistique, unité sémantique}, qui correspond à
l’association d’un mot et d’un sens précis. Chaque mot engendre ainsi autant
d’unités qu’il a de sens différents. Un travail équivalent est réalisé en
Europe par plusieurs équipes universitaires et industrielles, coordonnées par
l’Université d’Amsterdam : le projet EuroWordNet couvre 7 langues
européennes en plus de l’anglais : français, italien, espagnol, allemand,
hollandais, tchèque et estonien. Le vocabulaire de chacune de ces langues est
organisé sous forme d’un réseau sémantique, sur la base des concepts utilisés
par l’Université de Princeton. Des liens entre les termes des différents
réseaux sont crées, en vue des traitements multilingues, et en particulier de
l’interrogation translingue. Ces réseaux sémantique dans le cas du vocabulaire
courant peuvent être utilisés dans la réalisation d’outils comme celui présenté
ci-dessous.
ØAnciennement
chez Altavista : Live Topics
Alta Vista intègreait il y a quelques temps Live Topics (appelé aussi Cow9).
L'intérêt principal de cette fonction était de fournir à l'utilisateur une
liste de mots se rapportant au sens de la question et de pouvoir ainsi ajouter
à la question des termes auxquels il n'avait pas nécessairement pensé lors de
la formulation de sa requête initiale. Cette fonction était disponible
uniquement pour l'interface anglaise d'Alta Vista. Son utilisation était la
suivante (voir aussi illustration document 30):
1.
L'utilisateur pose une
question au moteur de recherche d'AltaVista.
2.
Celui-ci fournit la
liste de résultats.
3.
À ce stade,
l'utilisateur peut accéder à LiveTopics via le bouton
"Refine".
4.
Ces interfaces proposent
à l'utilisateur une liste de mots à la fois relatifs aux mots de la question
mais aussi contenus dans les documents résultats. L’utilisateur peut alors pour
chacun de ces mots, choisir de forcer la présence du mot dans les
documents qu’il veut rapatrier, d'interdire la présence du mot, ou tout
simplement ne pas prendre en compte ce mot. La carte représente l'ensemble des
thèmes identifiés par le logiciel pour une requête, ainsi que des liens entre
thèmes représentant une certaine forme de proximité (ou d'opposition)
sémantique.
5.
La question de
l'utilisateur sera donc reformulée en utilisant les opérateurs '+' et '-'
permettant respectivement de forcer la présence d'un mot ou de l'interdire.
6.
Enfin, l'utilisateur va
expédier de nouveau sa requête et obtenir éventuellement un nombre de résultats
restreints par rapport à sa demande initiale.
L’algorithme
utilisé, dit méthode des mots associés, utilise les cooccurences des
mots, qu’elle commence par regrouper en fonction de leur proximité (distance
physique) dans les textes. La position des mots dans le document devra pour
cela être précisée au niveau de l’index. En fonction de cette proximité, le
logiciel construit des grappes de mots, qui caractérisent des catégories
conceptuelles, ou des sujets d’intérêt. Cela donne à l’utilisateur une vision
globale des concepts recouverts par une requête, et lui permet d’en exclure
certains, donc d’affiner la recherche. Les concepts trouvés servent également à
établir une classification de l’ensemble des documents résultats. François
Bourdoncle, chercheur à l'Ecole des Mines de Paris, à l'origine de la
technologie de Live Topics est le fondateur du nouveau moteur Exalead http://www.exalead.com/ qui est lui aussi
basé sur une technologie de recherche interactive et itérative qui permet aux
utilisateurs de cibler leur recherche par choix successifs dans les réponses du
moteur. A chaque requête, le moteur analyse statistiquement l'ensemble des
résultats et donne une réponse sous forme de rubriques, de mots-clés qui
permettent d’affiner la requête par simples clics.
Les problématiques de l’accès à
l’information ont été étudiées depuis longtemps par les spécialistes de la
documentation et des sciences de l’information. Sans parler des systèmes de
gestion de bases de données, elles étaient jusqu’alors résolues par
l’utilisation de langages documentaires comme par exemple les thésaurus
utilisés pour référencer les documents. L’avantage est double. Leur structure
basée sur des associations de concepts suit notre mode de pensée et nous
guident ainsi efficacement vers le terme qui a servi à indexer le document. En
second lieu le référencement par rapport à ce terme aura été fait au préalable
par une personne qui aura lue le document et donc en aura extrait le sens.
L’utilisateur et l’indexeur s’expriment donc à travers le même référentiel.
Aujourd’hui ces thésaurus sont encore utilisés
efficacement pour indexer manuellement des banques de documents électroniques
et leur utilisation se fait à travers, comme nous l’avons vu, des interfaces
conviviales. L’indexation manuelle étant trop coûteuse, elle est peu à peu
remplacée par des logiciels capables d’extraire automatiquement le sens des
documents. Ceci grâce à l’utilisation des techniques de Traitement Automatique
du Langage Naturel. Les moteurs dits « sémantiques » sont alors
capable de proposer une recherche sur le sens du document. Malheureusement ces
technologies de plus en plus prometteuses sur des bases de documents
électroniques spécialisés s’appliquent difficilement sur une base documentaire
de la taille du Net. La quantité de documents à indexer sans cesse grandissante
ainsi que leur très grande hétérogénéité en terme de langage rend difficile
l’utilisation des ontologies pour l’indexation automatique. Certes les
annuaires basés sur un principe d’indexation manuelle tentent bien sûr de
proposer une vision structurée d’Internet et sont encore utilisés. Ils ne
peuvent cependant qu’aborder des sujets très généraux.
Alors le besoin de gagner en exhaustivité a conduit à
l’utilisation de systèmes d’indexation adaptés à des traitements automatiques
de masse : Altavista pouvait se vanter le 28 mai 2002 de mettre en ligne un nouvel index de 1,1 milliard de pages
web [19]. Le principe de l’indexation
en texte intégral est cependant bien loin de la notion de sens même si certains
traitements linguistiques tels que l’analyse morpho-syntaxique applicables dans
ce cas permettent de réduire grandement les ambiguités de langage. La
conséquence : un mode de recherche qui se révèle efficace à condition
d’utiliser des mots clés très précis dont la combinaison ne référence que peu
de documents. Dans le cas inverse, le résultat est souvent aléatoire et
l’utilisateur se voit submergé par une avalanche de résultats et le bruit est
énorme.
En conséquence plus de la moitié des internautes
passent plus de 70% de leur temps de connexion à rechercher l’information et
plus de 80% ne regardent que les tous premiers résultats retournés par les
outils de recherche lors d’une requête. C’est pourquoi la problématique
actuelle des outils de recherche n’est plus d’augmenter le taux de rappel (voir
paragraphe VI-3) mais la pertinence des résultats retournés avec une bonne
précision. Face à cela certains éditeurs ont contourné le problème en
développant des méthodes automatiques de classement indépendantes du contenu
des documents connues sous le nom de tri par popularité. Cependant ces
techniques défavorisent les pages récentes et donc inconnues.
Finalement seul les internautes comprenant la base du
mécanisme de fonctionnement de ces moteurs ont l’espoir d’en faire une
utilisation à peu près pertinente. Pour que les outils de recherche et
l’utilisateur s’expriment dans un même référentiel il devient nécessaire de
développer des interfaces intuitives qui doivent aider à formuler des requêtes
plus ciblées et quand c’est nécessaire affiner les résultats.
Cependant le support de l’information tend également
de plus en plus à s’enrichir d’éléments de structure décrivant de manière
formelle le contenu des documents à sa création. Ceci grâce à l’utilisation par
exemple du XML qui ne se contente plus comme le HTML de décrire seulement l’aspect
présentation (sauf présence de META TAG, voir paragraphe I-2-2). C’est
l’enjeux du Web sémantique que de permettre à des moteurs d’indexation et de
recherche d’extraire plus facilement le sens des documents et de les classer
automatiquement. Cette démarche s’inspire encore une fois d’une logique
documentaire. Cependant la tâche s’avère difficile. En effet comment imposer un
mode de pensée formalisée dans un monde aussi informel et instable que celui de
l’Internet. La solution idéale existera lorsque les progrès de l’intelligence
artificielle et du Traitement Automatique du Langage Naturel nous permettront
d’utiliser des outils capable d’extraire automatiquement le sens des documents
sans utiliser de bases ontologiques préétablies. En attendant les moteurs de
recherche traditionnels sont promis à bel avenir.
Références
citées dans ce rapport (sites Internet et articles) :
[1] Article
du Journal du net du jeudi 23 mars 2000 intitulé « Altavista consacre son
nouvel outil de recherche à l’e-business B-to-B » (http://solutions.journaldunet.com/00mars/000323altavista.shtml)
[2] Andrei
Broder, Ravi Kumar, Farzin Maghoul, Prabhakar Raghavan, Sridhar Rajogopalan,
Raymie Stata, Andrew Tomkins, Janet Wiener, « Graph Structure in the
Web » (www.almaden.ibm.com/cs/k53/www9.final/).
[3] White paper, “The Deep Web : Surfacing Hidden value”,
BrightPlanet.com LCC, July 2000 (www.completeplanet.com/Tutorials/DeepWeb/index.asp).
[4] Thésaurus de
Statistique Canada (http://www4.statcan.ca/francais/thesaurus/index_f.htm)
[5] American
National Standards Institute. Guidelines for the Construction, Format and
Management of Monolingual Thesauri (ANSI/NISO Z39.19 - 1993)
[5bis] Le MeSH bilingue 2002 (http://dicdoc.kb.inserm.fr:2010/basismesh/mesh.html)
[6] PubMed (http://www.ncbi.nlm.nih.gov/entrez/query.fcgi)
[7] [Lindberg 1990] Lindberg DAB,
Humphreys BL. The UMLS Knowledge Sources : Tools for Building
Better User Interfaces. In : Proc. 14th SCAMC. Washington, DC : IEEE.
1990; 121–125
[8] Joubert M, Robert JJ, Miton
F, Fieschi M. The project ARIANE: conceptual queries to information databases. Proc.
AMIA Annual Fall Symposium (Cimino J, ed). JAMIA Symposium Supplement,
1996: 378-382.url : http://www.hbroussais.fr/Cybermed/Laboratoires/Ariane.htm
[9] C.
FLUHR, “Le traitement du langage naturel dans la recherche d’information
documentaire », Interfaces intelligentes dans l’information
scientifique et technique, cours INRIA, Klingenthal (Bas-Rhin), mai 1992.
[10] http://www.abondance.com/outils/moteurs.html
[11]T-G.I.D.
84-88, boulevard de la Mission Marchand, 92411 Courbevoie cedex
Tél : 01 49 04 70 70 – Tlc : 01 43 33 95 79
marketing@technologies-GID.com – http://www.t-gid.com
Traitement du langage naturel : Spirit.
[Retour
au texte : 1) Le niveau morphologique]
[Retour au texte : 2) L’analyse syntaxique]
[12]VERITY France
14, place Marie-Jeanne Bassot, 92593 Levallois-Perret cedex
Tél. 01.41.49.04.50 - Tlc. 01.40.89.09.81
rep-France@verity.com - http://www.verity.com/international/france.html
Traitement du langage naturel : Search'97, Search'97 Agent
server, Search'97 Information Server, Search'97 Personal.
[Retour au texte : IV-2. L’indexation par mots clés]
[Retour au texte : L’exemple de Verity]
[13]SINEQUA (ex CORA)
51-59 rue Ledru Rollin, 94200 Ivry sur Seine
Tél : 01 49 87 06 00 – Tlc : 01 49 87 06 01
sinequa@sinequa.com - http://www.sinequa.com
Traitement du langage naturel, gestion électronique de documents et de
l'information : Darwin, Intuition. [Retour
au texte : II-2.1 Définition des moteurs de recherche]
[Retour
au texte : IV-4.2 Principes des techniques linguistiques d’indexation]
[Retour au texte : 1) Le niveau morphologique]
[Retour au texte : 2) L’analyse syntaxique]
[Retour au texte : 3)L’analyse sémantique]
[14]LEXIQUEST (ex. ERLI)
Immeuble Le Mélies, 261, rue de Paris, 93556 Montreuil cedex
Tél : 01 49 93 39 00 – Tlc : 01 49 93 39 39
alain.beauvieux@lexiquest.com - http://www.lexiquest.com
(en anglais)
Traitement du langage naturel : Lexiguide, Lexirespond, Leximine,
Terminology Maganer.
[Retour
au texte : IV-4.2 Principes des techniques linguistiques d’indexation]
[Retour au texte : 1) Le niveau morphologique]
[Retour au texte : 3) L’analyse sémantique]
[15]SYSTAL
Pertimm
[Retour
au texte : IV-4.2 Principes des techniques linguistiques d’indexation]
[Retour au texte : 1) Le niveau morphologique]
[Retour au texte : 2) L'analyse syntaxique]
[16] DATOPS NIMES
Parc Georges Besse
Allée Charles Babbage
30000 NIMES
+ 33 (0) 4 66 04 11 21
mail : info@datops.com
Produits :
Pericles, InfoMonitor, RiskMetrics
http://www.datops.com/ [Retour au texte]
[Retour au texte : III-2. Les agents de recherche automatique]
[Retour au texte : 1) Le niveau morphologique]
[Retour au texte : 2) L’analyse syntaxique]
[Retour au texte : L’exemple des produits Datops]
[17] F. BISSON, J. CHARRON, C. FLUHR, D. SCHMIT, « EMIR at the CLIR
track of TREC-7 », Proceedings of the Seventh Text Retrieval Conference
(TREC-7), Gaithersburg, Maryland, 9-11 novembre 1998, p. 337-342
[18] K.
LESPINASSE, “TREC, Une conference pour l’évaluation des systèmes de recherche
d’information », Documentaliste, vol. 34, n°2, 1997.
[19] Actualité
en ligne du site abondance « 1 milliard de
pages web pour Altavista » http://actu.abondance.com/actu0224.html
[20] http://www.copernic.com/fr/desktop/products/agent/professional.html
[21] http://www.copernic.com/fr/desktop/products/summarizer/
[22] http://solutions.journaldunet.com/0106/010606_lexiquest.shtml
[23] Brewster Kahle invente le Wide
Area Information Server (WAIS) en 1991 : http://www.info.uqam.ca/~probst/I1051c11.html
[24] Robertson S. E., Sparckjones K. « Relevance
weighting of search terms », Journal of the American society for
Information Science, 27 (3): 129-146, 1976.
[25] Lawrence Page, Sergey Brin, Rajeev Motwani, Terry
Winograd, "The PageRank Citation Algorithm: Bringing Order to the Web".
[26] SALTON G, WU H, YU C.T. : “The Measurement of Term
Importance in Automatic Indexing”, Journal of Asis, n°3, 1981, pp.175-186
Livres :
Trouver l’info sur l’Internet
Olivier
ANDRIEU
Eyrolles,
mars 1998
La recherche d’information du texte intégral au thésaurus
Philippe
Lefèvre
Hermès,
Sept.2000
La recherche intelligente sur
l'internet et sur l'intranet (2° Edition)
SAMIER Henry, SANDOVAL Victor
Date
de parution: 09-1999
Ed Hermès
Recherches
sur Internet
(2° Edition)
Gilles Fouchard
Campuss Press, 1999
L’information
scientifique et technique et l’outil Internet (CNRS)
Le
Micro Bulletin Thématique n°3
Moteurs d’indexation et de recherche
Catherine LELOUP
Eyrolles, 1998
Recherche et veille sur le Web visible
et invisible
Béatrice
Foenix-Riou
Tec&Doc,
2001
Les aides à la recherche
Gabriela
Gavrilut
Edition
TRECARRE
Data mining
Gestion
de la relation client. Personnalisation de sites web
Rapports :
Les mécanismes
de recherche d’informations utilisé par Google
Rapport
Probatoire
Soutenu
le 25 avril 2002 par Pablo RAKOVEC au CNAM (Centre Régional
Languedoc-Roussillon)
Les agents de
recherche sur Internet, une architecture d’Agents : les Agents Mobiles
Rapport
Probatoire
Soutenu
le 16 juin 2000 par Pierre-François De CARLINI au CNAM de TOURS
http://www.ctn.asso.fr/Fr/Sti/internet/rechinfo/agentsmobiles.pdf
Indexation
automatique : un état de l’art
Mémoire
de Maîtrise de sciences du langage
Présenté
par V.COMBET à l’Université Paris-X NANTERRE (Septembre 1997)
http://www.sinequa.com/sq-lab-doc/maitrise-combet.pdf
Les moteurs de
recherche
Exposé
Multimédia 2001
FRESNAU
Patrice
EPITA
PROMO 2002 Multimédia
http://mma.epita.net/downloads/veille/veille2002/000088_Moteur%20de%20recherche.pdf
L’indexation
automatique
Note
de Synthèse
DEA
Sciences de l’information et communication
Ecole
Nationale Supérieure des Sciences de l’Information et des Bibliothèques
(ENSSIB)
Mabrouka
EL HACHANI (Mars 1997)
http://www.enssib.fr/bibliotheque/documents/dea/elhachani.pdf
Le repérage de
l’information sur Internet : catalogage et indexation des ressources sur
le WWW
Mémoire
de maîtrise des Sciences de l’Information et de la Documentation
Présenté
par Diego-Angel DIAZ en Novembre 1998,
Université
de Paris I Panthéon-Sorbonne
http://membres.lycos.fr/ddiaz/
url de certains moteurs de recherche sur Internet
cités dans ce rapport [Retour au texte]
![]() AltaVista http://www.altavista.com
AltaVista http://www.altavista.com
![]() Google http://www.google.com
Google http://www.google.com
![]() Excite http://www.excite.fr
Excite http://www.excite.fr
![]() WebCrawler http://www.webcrawler.com
WebCrawler http://www.webcrawler.com
![]() Lycos http://www.lycos.fr
Lycos http://www.lycos.fr
![]() NorthernLight http://www.northernlight.com
NorthernLight http://www.northernlight.com
![]() Infoseek http://www.infoseek.com
Infoseek http://www.infoseek.com
![]() HotBot http://www.hotbot.com
HotBot http://www.hotbot.com
 Lockace http://www.lokace.com/
Lockace http://www.lokace.com/
![]() All The Web http://www.alltheweb.com
All The Web http://www.alltheweb.com
![]() Voila http://www.voila.fr
Voila http://www.voila.fr
![]() Teoma http://www.teoma.com
Teoma http://www.teoma.com
![]() Looksmart http://www.looksmart.fr
Looksmart http://www.looksmart.fr
![]() Vivissimo http://vivisimo.com/
Vivissimo http://vivisimo.com/
![]() Exalead http://www.exalead.com
Exalead http://www.exalead.com
Moteurs de recherche pour site Intranet disponibles
graduitement

voir aussi pour installer et
configurer Ht://dig pour la langue française :
http://www.quartier-rural.org/dl/elucu/htdig-vf/
Le système ht://Dig est un moteur de recherche complet servant à indexer à travers un petit domaine internet ou d'un intranet. Il a été conçu pour combler les besoins en recherche pour une compagnie unique, un campus ou encore pour être une composante particulière d'un site WEB. Il ne peut remplacer le besoin d'un puissant moteur de recherche qui s'étale à travers Internet tel que Yahoo, Lycos, Infoseek, Webcrawler et AltaVista.
À l'opposé des moteurs de recherche de type WAIS ou montés sur un serveur WEB, ht://Dig peut s'étendre sur plusieurs serveurs WEB constituant un site WEB. Le type de serveur WEB utilisé n'a aucune importance, en autant qu'il supporte le protocole HTTP 1.0.

Swish-E est un autre moteur de recherche. Plusieurs fonctionnalités le rende unique. Voici quelques-unes de ses particularités:
- Ultra rapide - Plusieurs facteurs
peuvent venir affecter la vitesse d'exécution, par contre, on peut prédire
qu'une recherche sur le présent serveur et ce, à travers des milliers de
documents, ne prendra que quelques secondes.
- Flexible - une panoplie d'options de
configuration procure un haut degré de contrôle sur les fichiers qui
doivent être indexés ainsi que sur leur manière d'indexage.
- Puissant - Les opérateurs AND, OR et NOT
sont supportés. Les mots peuvent également être coupés en utilisant
le caractère * . De plus, les recherches peuvent être limitées
à certain champs (ex: META tag fields, TITLEs, etc).
- Simple - Une fois installé, configuré,
et que les usagers sont autorisés, un administrateur de site WEB peut
façilement créer et maintenir des indexes sur son site.
Vous pouvez regardez le démonstrateur AutoSwish pour voir comment il fonctionne.
Swish-E est fait pour les sites WEB - en indexant des fichiers HTML. SWISH-E peut ignorer la plupart des tags pendant qu'il est à la recherche d'informations pertinentes dans les "headers" et dans le "title tags". Les Titles sont extrait du fichier HTML et sont affichés dans le résultat de recherche.
SWISH, automatiquement, cherche à travers la totalité d'un site WEB en une seule passe, si la recherche s'effectue sous un seul répertoire. La recherche peut aussi se limiter à un mot dans le titre HTML, un commentaire, tag emphasé et META tags. De plus, les caractères 8-bit HTML peuvent eux aussi être indexés, convertis , et recherchés.
Il crée des indexes petits et portables - afin d'indexer; tous les fichiers, il n'a besoin que d'un seul fichier. Donc il est portable et demande peu de maintnance. Le code source SWISH-E ne prend pas de place et les indexes sont, en moyenne, au environ de 1 à 5% de la taille du fichier HTML original.

http://glimpse.cs.arizona.edu/
Webglimpse search engine software includes a web administration
interface, remote link spider, and the powerful Glimpse file indexing and query system.
Quickly and easily add search capability to your site.
Webglimpse
is scalable: index one small local site, hundreds of remote sites, or
gigabytes of compressed documents. The code is open, mature, widely used, and
actively supported.

http://www.objectweaver.de/ice/ice.html
ICE is an easy to install software package for
indexing World Wide Web archives. By installing it as a CGI gateway under your
Web server, users can perform searches on the Web servers document space.
Harvest
http://www.tardis.ed.ac.uk/harvest/
http://harvest.cs.colorado.edu/
WAIS
http://ls6-www.informatik.uni-dortmund.de/freeWAIS-sf/
ftp://iml.univ-mrs.fr/pub/barthelemy/wais-94.txt
Structure et formats des fichiers d’index[Retour au texte]
I Structure des index
ØParamètres des index
Parmi les paramètres des fichiers d’index qu’il est
important de prendre en compte, il y’en a au moins deux, essentiels : la
longueur des entrées d’index (la longueur des mots que le logiciel
traite lors de l’indexation généralement fixée de 40 à 60 caractères) et la
normalisation des index.
La normalisation des index correspond à une gestion
des entrées sous forme de termes en caractères majuscules, ou plus exactement
sans prise en compte des caractères accentués.
Il est vrai qu’en langue anglaise cela n’a guère
d’importance, et la quasi-totalité des logiciels sont d’origine nord-américaine
ou anglo-saxonne. En revanche, en français ou dans des langues utilisant toutes
formes d’accents et de signes dits diacritiques, cela peut en avoir beaucoup
plus. En effet, si les index sont normalisés en majuscules, les mots crèpe et
crêpe seront indifférenciés et toutes les notices et les documents les
concernant seront indexés à CREPE.
ØIndex monochamps
Le contenu d’un champ des documents est indexé dans
un seul fichier d’index. Ainsi, pour une base d’information où vous aurez
défini les champs Titre, Auteur, Mots clés, Texte, vous pourrez avoir quatre index monochamps respectivement sur le Titre, l’Auteur, les Mots clés, le Texte.
ØIndex multichamps
Ce sont des fichiers d’index qui rassemblent, pour
une même entrée, plusieurs index des champs de la notice ou des documents.
Prenons le cas où l’on aurait structuré notre base
avec les champs Titre, Résumé et Texte.
Dans bien des cas, lorsque l’utilisateur va rechercher un texte, il ne saura pas dans quel champ effectuer sa recherche. Il peut donc être très intéressant de lui offrir une recherche sur le contenu des 3 champs ensemble. On créera alors un index multichamps dans lequel pour chaque entrée de l’index on aura l’information des documents qui contiennent le terme dans l’un au moins des trois champs Titre, Résumé, Texte.
ØIndex multibases
Cette fois-ci, l’index va porter sur les champs de
plusieurs documents de plusieurs bases d’informations à la fois. Cela est utile
pour éviter à l’utilisateur de faire les mêmes recherches successivement dans
diverses bases.
II - Format des fichiers d’index
La structure physique et logique des fichiers
d’index est propre à chaque moteur. Cependant les principales techniques
utilisées s’appuient sur les structures de fichier séquentiel indexé,
essentiellement pour des index mots clés ou mots à un ou plusieurs niveaux. Plusieurs
niveaux mettent en jeu une cascade de fichiers reliés par des pointeurs :
ainsi on aura un fichier mots (ou lexique), un fichier ordonné par mots,
listant pour chacun d’eux les documents concernés, et un troisième fichier
contenant les positions.
Une autre technique fréquemment utilisé est celle du
B-tree, qui revient également à organiser une structure hiérarchique des index.
Des bases de données hiérarchiques ou relationnelles peuvent également être utilisées pour stocker les index.
III - Gestion et mise à jour des index
Dès qu’un document est mis à jour, les fichiers
d’index sont modifiés en conséquence. Il s’agit d’éliminer la référence du
document pour les entrées d’index supprimées et d’insérer la référence du
document pour les entrées d’index ajoutées. Si un document est supprimé, par
exemple parce qu’il est trop ancien et ne présente plus d’intérêt, c’est
exactement le même scénario. Plus la base d’information évolue et plus le taux
de mise à jour des fichiers d’index est important.
De plus, lorsque trop de suppression ont été
effectué sur un index, il est fortement conseillé de le reconstruire,
c’est-à-dire de le recréer complètement. Les logiciels fournissent souvent des
indicateurs qui permettent d’évaluer la bonne santé des index, en règle
générale, fondée sur leur taille.
Autrefois, la mise à jour des index était
systématiquement effectuée en temps différé, pour ne pas dégrader les
performances de recherche. Cela reste encore vrai, mais les technologies des
moteurs d’indexation et de recherche ont évolué pour autoriser aujourd’hui une
mise à jour de l’indexation en temps réel ou une mise à jour programmée en
léger différé, de manière cyclique, avec une constante de temps éventuellement
paramétrable.
Les index mots clés ont une taille assez limitée,
liée au nombre de mots clés autorisés. Elle est typiquement de quelques
milliers d’entrées. A titre comparatif, un index mots ou texte intégral va en
contenir plusieurs dizaines de milliers.
La tailles des fichiers d’index dépend aussi des technologies
des moteurs d’indexation et de recherche. Ainsi, un fichier d’index mots clés
aura environ 0,5 fois la taille du champ source correspondant. Pour un fichier
d’index en texte intégral, ce taux varie de 0,3 à 1,5 fois la taille du champ
source, selon la technique et la technologie utilisées.
Le facteur d’expansion des bases d’information est
le ratio de la taille de la base, index compris, à la taille des fichiers
documents. Il varie ainsi de 1,3 à 2,5 selon les types d’index utilisés et les
technologies des moteurs d’indexation et de recherche. Cela reste raisonnable
compte tenu du prix actuel de l’espace disque.
Cependant
il y a un compromis à réaliser entre les performances de recherche et la
fraîcheur des index, puisque ce sont les mêmes fichiers physiques qui sont
utilisés.
ANNEXE 4[Retour au texte : 1)Le
niveau morphologique]
[Retour au texte : mode
recherche en langage naturel]
Ces entreprises proposent des outils de recherche qui permettent l’interrogation en langage naturel :
Lexiquest a créé des technologies de
pointe en matière de traitement linguistique. La technologie de base est le
fruit de plus de vingt ans de recherche. Résultat : les applications de
traitement linguistique évoluées sont plus performantes et plus satisfaisantes.
La technologie LexiQuest est capable de traiter les différents échelons du
langage naturel :
- morphologique : compréhension du
mot, y compris des différentes formes du mot, des mots composés et des
catégories grammaticales ;
- syntaxique : identification des
fonctions des mots dans une phrase ;
- sémantique : identification de
la signification du mot selon son utilisation ;
- conceptuel : organisation des
concepts indépendamment de la langue.
Technologies-GID propose le moteur de
recherche en langage naturel SPIRIT V2. La question, posée en langage parlé,
est analysée comme les textes, assurant ainsi la cohérence et la performance du
traitement. SPIRIT V2 s'appuie pour le français sur un dictionnaire de 500 000
entrées comprenant des mots avec toutes leurs formes dérivées. Pour l'anglais,
un dictionnaire d'environ 100 000 entrées est utilisé. SPIRIT V2 possède un
dictionnaire de reformulation qui permet un élargissement de la recherche aux
synonymes et termes de même famille. Par exemple, « la sécurité des
installations... » retrouve aussi « la sûreté des installations... » . SPIRIT
V2 est livré en standard avec plus de 130 000 règles de reformulation
françaises correspondant aux synonymes usuels de la langue, termes de la même
famille, etc.
Classement établi dans le magazine en ligne
« le Journal du Net » :
http://solutions.journaldunet.com/0108/010829_panoramamoteur.shtml
|
Moteurs
de recherche: le tableau des solutions |
||||||||||||||||||||||||||||||||||||||||||||||||
|
(MIS A
JOUR LE 26/11/2001)
|
||||||||||||||||||||||||||||||||||||||||||||||||
Exemples d’intégration de moteurs dans le cadre de site Web :
http://solutions.journaldunet.com/0203/020312_moteur.shtml [Retour au texte]
Booléens, sémantiques, syntaxiques... La meilleure façon d'appréhender un moteur de recherche, c'est encore de l'essayer. Pour les principales solutions du marché, JDNet Solutions a identifié des exemples de mises en oeuvre, dans le cadre de sites web (dont nous indiquons les adresses) et d'intranets.
|
Les moteurs sémantiques
généralistes |
||
|
éditeurs/solutions |
Les sites Web |
Les intranets |
|
Verity
|
Le site Web
communautaire Multimania
(groupe Lycos). |
Les
intranets documentaires de Pechiney, Schneider Electrique, Airbus et Thomson. |
|
Arisem |
Les
sites d'atmedica,
de Lexmark et de l'Usine Nouvelle. |
Les
intranets du Groupe Pernod Ricard, de Radio France et du CNES (Centre
Nationale d’Etudes Spatiales). |
|
Sinequa |
Les
sites des 3 Suisses,
de La Redoute,de Leroy Merlin et d'Allociné. |
Les
systèmes de gestion de contenu de Thomson CSF, de Saint Gobin, de la SNCF et
de Ouest France. |
|
Hummingbird
|
La
boutique en ligne de Carrefour, ainsi que des sites du CCF et de la BNP. |
Les
services d'information du gouvernement, la Bibliothèque Nationale et la base
documentaire de la Commission Européenne. |
|
Convera |
Webencyclo (Atlas), le
service de recherche d'emplois CareerBuilder, et le client Web de l'Electronic
Online Systems International (une base de données universitaire). |
Un outil
de veille concurrentielle chez Air France, des intranets chez PSA et Bouygues
Telecom, le système de gestion documentaire vidéo de Canal+ Belgique. |
|
Inktomi |
Les
portails de MSN, d'AOL et de Hotbot, et les sites de NBCI. |
|
|
Les moteurs sémantiques
généralistes/Web |
||
|
Atomz |
Les
sites de CBS,
de 3M et de Macromedia. |
|
|
Delphes Technologies International |
Les
sites BellZinc
(Bell) et du Centre de Promotion du Logiciel
Québécois. |
|
|
Les
moteurs de recherche statistiques |
||
|
TripleHop |
Les
sites de voyage Orbitz,
OneTravel et 11th Hour
Vacations. |
Les
intranets de JC Decaux et d'AOL Time Warner. |
|
Autonomy |
Le
portail de TF1 notamment. |
Les systèmes
de gestion documentaire des sociétés pharmaceutiques Astra Zeneca et Pfizer. |
|
Les
moteurs de recherche multi-dimensionnels |
||
|
Instranet |
|
Les
systèmes de gestion de contenu de la BNP, du Crédit Lyonnais et de Système U. |
|
Les assistants de requêtes |
||
|
LexiQuest |
Les
sites du Centre
Français du Commerce Extérieur (CFCE) et de l'Institut National de la Propriété
Industrielle (INPI) |
Les
intranets du cabinet de conseil Accenture, de la BNP et du Crédit Agricole. |
|
Albert |
Le
portail de RFO
(Réseaux France Outremer) |
|
|
Auracom |
Les
sites du forum des
images, de la CNAMTS (Caisse
Nationale d'Assurance Maladie) de l'ONISEP et de l'Elysée.
|
Le
portail intranet de la CNAMTS (Caisse Nationale d'Assurance Maladie). |
Le mode recherche avancé d’Altavista [Retour au texte]
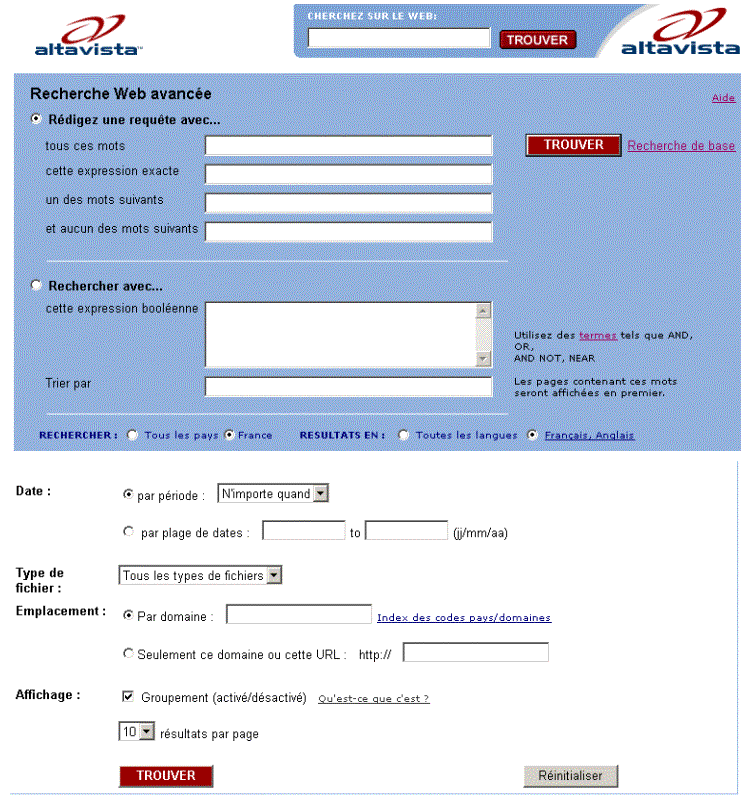
Principales fonctionnalités d'Intuition version 3 [Retour au
texte]
La liste, présentée ci-dessous, mentionne différentes fonctionnalités disponibles dans Intuition. Cette liste, non exhaustive et non structurée, vise principalement à noter des atouts qui peuvent être déterminants dans le choix de la technologie Intuition, notamment en regard des produits concurrents.
• Choix de la langue pour les requêtes : La requête peut-être
formulée dans une des langues suivantes: anglais, français, allemand, espagnol,
italien, néerlandais, suédois, norvégien, danois, polonais, japonais, chinois,
et thaïlandais.
Cependant une véritable analyse linguistique n'est effectuée qu'en
anglais, français, allemand, espagnol, japonais et bientôt italien et
néerlandais.
Les quatre première langues citées bénéficient en outre d'un parfait interlinguisme.
• Dictionnaires additionnels : La spécialisation d’Intuition dans un vocabulaire particulier se fait grâce à la création de dictionnaires sémantiques additionnels (dictionnaire du bricolage, du droit, etc.)
• Topiques : Les documents indexés sont « rangés » dans de grandes catégories thématiques (alimentation, politique, sport, sciences, etc.)
• Désambiguïsation : Une requête peut être jugée ambiguë par Intuition.
Il demande alors à l’utilisateur de préciser le sens de certains mots
polysémiques au moyen de grandes familles de sens.
( Ex : avocat = métier | droit | botanique | alimentation )
• Calcul et affichage des concepts : L’affichage d’un document peut être accompagné du surlignage des groupe nominaux comprenant au moins un mot important de la requête, aussi bien dans les document HTML que Pdf
• Découpage des documents : Pour la recherche sémantique et pour faciliter la lecture des réponses, un document trop gros peut-être découpé automatiquement au moment de l’indexation. Un élément de réponse sera alors un morceau du document initial mis en évidence au sein du document entier.
• Titre et extrait : Au cours de l’indexation des documents, un titre et un extrait sont détectés au début du texte, en vue de les afficher dans la liste des réponses. Dans le cas des documents HTML et PDF, le titre correspondra respectivement au contenu de la balise <TITLE> et de la zone INFO des documents.
• Champs structurés : L’indexation plein texte des documents s’accompagne de la définition et de l’affectation de champs structurés paramétrables. Certains champs prédéfinis sont optionnels (titre, abstract, date d’indexation, taille du document). D'autre champs utilisateur seront déclarés lors de la création des bases d'index.
• Vectorisation des mots : Lors de l’analyse d’une requête, en plus du vecteur sémantique de la requête, on attribue un vecteur à chaque mot de la question. Ceux-ci permettent de savoir, pour une réponse donnée, quels ont été les mots déterminants.
• Propositions de stratégies de recherche : L’utilisateur a la
possibilité d’effectuer une recherche principalement par les mots ou par
les sens, exclusivement par les mots ou par le sens, ou par les deux de
façon équivalente.
Il est bon de pouvoir régler ce paramètre en fonction du niveau de
précision souhaité dans le choix des réponses.
• Affichage par pertinence et réglage des seuils minimaux : Dans Intuition, les réponses sont affichées par défaut par pertinence décroissante. Toute réponse s’accompagne de trois indices de pertinence différents (pertinence sur les mots, pertinence sur le sens, pertinence globale). Le troisième, combinaison des deux premiers, est le plus important.
Trois seuils de pertinence minimaux permettent à l’utilisateur de demander au système de ne pas afficher les documents réponses dont l’un des indices est inférieur au seuil spécifié. Parmi les nouveautés, il est possible de définir une pertinence minimale relative à celle de la meilleure réponse.
• Recherche par l'exemple : Une fonction de navigation particulièrement intéressante dans Intuition consiste à poser en requête la totalité d’un document proposé dans une liste de réponses antérieure.
• Fonction d'affinage : C'est une autre fonction de navigation. Dans une liste de réponses, le fait de qualifier comme bons ou mauvais les documents au gré des consultations, permet d’apprendre au système vos attentes réelles. La fonction d’affinage permet alors de reposer la requête correspondante, afin de rectifier la pertinence de chaque réponse.
• Regroupement des URL par sites : Lors de l’indexation de documents, il est possible de déclarer que certains documents appartiennent à un même ensemble. (Exemple typique : toutes les pages d’un même site Web). Le but de ce regroupement est de n’afficher dans les listes de réponses qu’un seul représentant de chaque ensemble. Cette fonction est particulièrement utile sur un ensemble de sites Web.
• Recherche floue : Pouvant être branché ou non au moment de l’indexation, le module de recherche floue permet d’étendre la recherche. Il s’applique aux mots inconnus de la requête pour lesquels il est possible de trouver, dans la base, des mots proches (noms communs ou noms propres), à un ou plusieurs caractères près.
• Synonymie : Il est possible de brancher, dans Intuition, des dictionnaires de synonymes. Ceux-ci peuvent être réalisés par le client au moyen d’un module d’administration Windows, ou à l’aide d’un simple éditeur de texte.
• Nominalisation : Il est possible de brancher dans Intuition un module permettant d’élargir la recherche sur les verbes, par l’ensemble des noms de même famille morphologique. (ex. : accentuer à accent, accentuation)
• Phonétisation : Lorsque la recherche porte sur un mot mal orthographié, il est également possible d'effectuer un élargissement phonétique.
• Skip-list : En dernier recours, si l’analyse est jugée non satisfaisante pour certains mots outils, il est possible d'exclure ces derniers en les listant dans un fichier particulier.
• Génération de logs : Le serveur Intuition génère un fichier de logs, qui trace toutes les requêtes traitées, avec indication de leur provenance, l’heure à laquelle la question a été posée, les éventuels problèmes rencontrés. Cela permet en outre de comptabiliser le nombre de requêtes reçues par le serveur dans un laps de temps donné.
Questionnaire relatif aux produits de la societe
datops [Retour
au texte]
GENERALITES
Description de la société
Nom de la société :
DATOPS
Adresse : 113 Bd Haussmann
Téléphone / Fax : +33 (0)1 43 12 37 80
Contact commercial : adyevre@datops.com
L’enjeu :
à l’aide de modèles mathématiques évolués, traiter de gros
volumes d’information textuelle afin d’en dégager les tendances et les
composantes.
Les défis technologiques :
Ÿ capter et
indexer en temps réel de gros volumes de données issus de sources disparates
(traitement des grands flux continus d’informartions : les flux de presse
et de toute source internet – 13000 sources presse-newsgroups- web) ,
Ÿ gérer le
multilinguisme (mise en œuvre de toute une gamme d’outils d’analyse capable de
s’adapter à toute langue et à toutes forme de discours – de l’analyste
financier à l’activiste),
Ÿ accéder au
sens du discours (outils d’analyse de contenu – détection des thèmes et des
associations de thème, mesures),
I CARACTERISTIQUES GENERALES
Historique du système
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Nom de produit : |
Pericles |
InfoMonitor |
RiskMetrics |
|
Date de conception : |
1996 |
2001 |
2001 |
|
Nombre de clients [MSOffice1]: |
10 |
20 |
1 |
|
Numéro de la dernière version : |
2.5 |
2.05 |
1.1 |
|
Date de la dernière version : |
Juin 2002 |
Juin 2002 |
Mars 2002 |
OFFRE DE
TRAITEMENTS LINGUISTIQUES
Fonctionnalites du systeme
La liste des fonctionnalités du système qui sera
décrite dans la partie caractéristique fonctionnelle est la suivante :
-
Récupération automatique de contenu
-
Système d’indexation
-
Interface de recherche
-
Organisation des documents récupérés
-
Exploitation des résultats
-
Navigation à travers les résultats
-
Domaine d’application
Performances
Formats des données en entrée :
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Structuration des documents |
non |
non |
non |
|
Jeux de caractères admis (normes ISO et
autres standards). Si oui, le(s)quel(s) |
ISO latin et unicode |
ISO latin et unicode |
ISO latin et unicode |
|
Traitements de documents composites |
non |
non |
non |
|
Fichiers admis |
Traitement de texte, pdf, XML, SGBD |
Traitement de texte, pdf |
Traitement de texte, pdf |
Langues :
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Langue(s) des documents en entrée |
multilingues |
Multilingues |
multilingues |
|
Langue(s) de dialogue avec le système |
Anglais |
Anglais/Français |
Anglais |
Volume traité :
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Nombre de documents maximum acceptés par le
système (capacité maximale en octet) |
700 000 docs 7 Go de docs |
700 000 docs 7 Go de docs |
700 000 docs 7 Go de docs |
Temps moyen de traitement en Mega Octet pour PC (vitesse 1GHz)
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Indexation |
200 Mo/heure |
200 Mo/heure |
200 Mo/heure |
|
Interface de recherche |
8 sec maxi par requete sur index de 900 Mo (140
docs) |
8 sec maxi par requete sur index de 900 Mo (140
docs) |
8 sec maxi par requete sur index de 900 Mo (140
docs) |
|
Organisation |
55 Mo/heure |
55 Mo/heure |
55 Mo/heure |
|
Exploitation |
Interactif |
Non |
30 Mo/heure |
II Traitements et Analyses linguistiques
Ressources linguistiques : base de rêgles d’extraction et de taggage linguistique
Versions
disponibles anglais, français
Vocabulaire associé
Dictionnaires
|
Langues |
Produit
1 |
Produit
2 |
Produit
3 |
|
Dictionnaire monolingue Plusieurs dictionnaires monolingues avec liens
interlangues (préciser les langues) Dictionnaires multilingues (préciser les langues) |
Non Traduction automatique non |
Non Traduction automatique non |
Non Traduction automatique non |
Système sémantique
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Thésaurus Réseau sémantique Ontologie Base de connaissance |
non prévu début 2003 non non |
non prévu début 2003 non non |
non prévu début 2003 non non |
|
Multilingue |
non |
¨
oui / ¨
non |
¨
oui / ¨
non |
Grammaires associées
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Type de grammaire Grammaire syntagmatique Grammaire d’unification Autre : |
oui la mesure de tonalité se fait par unification |
oui la mesure de tonalité se fait par unification |
oui la mesure de tonalité se fait par unification |
|
Langues d’application |
Anglais, francais |
Anglais, francais |
Anglais, francais |
|
Mise à jour. |
Toutes les 2 heures |
Toutes les 2 heures |
Toutes les 2 heures |
Traitements linguistiques
|
Analyse
morpho-lexicale |
Produit
1 |
Produit
2 |
Produit
3 |
|
découpage de mots extraction des mots et termes complexes extraction des locutions extraction des mots inconnus lemmatisation nominalisation accentuation reconnaissance des sigles et abréviations reconnaissance des dérivations reconnaissance des formes fléchies reconnaissance des variations orthographiques correction orthographique |
Oui oui oui oui non oui non non non non non non |
Oui oui oui oui non oui non non non non non non |
Oui oui oui oui non oui non non non non non non |
|
Analyse
syntaxique |
Produit
1 |
Produit
2 |
Produit
3 |
|
Prise en compte des expressions disjointes et des
Coordinations (ex : juridiction étrangère = juridiction d’instruction et
juridiction étrangère) Extraction des mots et termes complexes Reconnaissance des homographes Reconnaissance des groupes nominaux et verbaux Reconnaissance des variations morpho-syntaxiques Reconnaissance des syntagmes nominaux Traitement des phrases négatives Traitement des reprises lexicales |
Non Oui Non Oui ? oui pris en compte dans la mesure de
tonalité non |
Non Oui Non Oui ? oui pris en compte dans la mesure de
tonalité non |
Non Oui Non Oui ? oui pris en compte dans la mesure de
tonalité non |
|
Analyse
sémantique |
Produit
1 |
Produit
2 |
Produit
3 |
|
Traitement des synonymes Notamment des mots et
termes étranger Traitement des non préférentiels ou
non-descripteurs Gestion des hiérarchies Traitement de la polysémie Avec analyse lexicale
pour lever les homographies Par simple appariement
d’une liste de mots vides Traitement des mots associés Traitement des concepts implicites |
Non Non Non Prévu début 2003 non |
Non Non Non Prévu début 2003 Non |
Non Non Non Prévu début 2003 non |
|
Analyse
statistique |
Produit
1 |
Produit
2 |
Produit
3 |
|
Fréquence absolue Avec prise en compte
des synonymes Fréquence relative Avec prise en compte
des synonymes Recherches des cooccurrences Avec prise en compte
des synonymes Modèles statistiques appliqués : Fréquence des segments
répétés Fréquence des quasi
segments Fréquence des syntagmes
répétés Fréquence des
groupes nominaux Fréquence des
syntagmes nominaux Construction de
tableaux, si oui : Binaire Contingence Transactionnel
(symétrique) Autres : |
oui non oui non oui non non non non oui oui non |
oui non oui non oui non non non non oui oui non |
oui non oui non oui non non non non oui oui non |
|
Autres
traitements appliqués à la linguistique |
Produit
1 |
Produit
2 |
Produit
3 |
|
Analyse pragmatique (analyse contextuelle ou de
la situation EX : moteur d’inférence) Analyse phonologique (identifier par
approximation des mots mal orthographiés) Approximation par recherche floue |
Non Non Prévue début 2003 |
Non Non Prévue début 2003 |
Non Non Prévue début 2003 |
II Caractéristiques fonctionnelles
Récupération automatique de contenus :
Les fonctionnalités sont les mêmes pour les 3
produits
Elle s’effectue à deux niveaux :
ØRécupération
automatique de documents sur Internet :
Les programmes associés avec capture des pages identifiées
sont : Méta-moteurs, Crawler, aspirateurs de sites et programme de
structuration de contenus avec extraction de contenu sur un ensemble de 2000
sites, tags.
Au niveau des fonctionnalités :
- il y a possibilité de récupération de pages dynamiques par
exemple : en paramétrant des requêtes http, en poursuivant des liens
visibles …
- protocoles intégrés : seulement http.
- Soumission de formulaires (moteurs de recherche interne,
SSL, authentification)
Ø Récupération
automatique de documents dans des sources internes :
Il y a connexion au système d’information SQLserver.
Au niveau des fonctionnalités :
- il y a possibilité de récupération de pages dynamiques par
exemple : en paramétrant des requêtes http, en poursuivant des liens
visibles …
- protocoles intégrés : seulement http.
- Soumission de formulaires (moteurs de recherche interne,
SSL, authentification)
La collecte des documents mets en œuvre une technologie
linguistique par analyse Morpho lexicale et synthaxique.
L’objectif du traitement
linguistique est de filtrer les pages collectées en diminuant le bruit.
Système d’Indexation
|
Nature
de l’indexation |
Produit
1 |
Produit
2 |
Produit
3 |
|
Indexation en entrée (documents) Indexation en sortie (requêtes) [indexation des
termes de la requête] Création d’index de tous les mots du
texte [tous les mots sont indexés sans sélection] Création d’index de tous les mots significatifs
[exclusion des mots vides] Création d’index des mots significatifs
lemmatisés Indexation par assignation [substitution du terme
par un terme préférentiel] Indexation sélective : par méthode statistique par méthodes des
cooccurrences Autres formes de modélisation du contenu sans
fichier d’index : catégorisation
automatique cartes sémantiques |
Oui Non Oui Paramétrable par l’utilisateur Non Non Non non |
Oui Non Oui Paramétrable par l’utilisateur Non Non Non Non |
Oui Non Oui Paramétrable par l’utilisateur Non Non Non non |
|
Etes-vous le concepteur du système
d’indexation ? Si non, quelle technologie utilisez-vous ?
(ex : fulcrum) |
Oui |
Oui |
oui |
|
Forme
de l’indexation |
Produit
1 |
Produit
2 |
Produit
3 |
|
Indexation non structurée [fichier d’index sous
la forme d’une liste] Indexation positionnelle |
Oui oui |
Oui Oui |
Oui oui |
|
Indexation structurée. Si oui : pondération explication des
descripteurs création de liens indicateurs de rôle autopostage |
Non |
Non |
Non |
|
Processus
d’indexation |
Produit
1 |
Produit
2 |
Produit
3 |
|
Codification totalement automatique |
Oui |
Oui |
oui |
|
Système assisté par l’homme |
Non |
Non |
Non |
Interface de Recherche
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Intégration d’un module de recherche. Si oui,
décrivez-en les fonctionnalités : |
Recherche full text Recherche multicritères Browsing graphique |
Recherche full text Recherche multicritères |
Recherche full text Recherche multicritères |
|
Traitements linguistiques des requêtes
(préciser le cas échéant) : Analyse morpho-lexicale Analyse syntaxique Analyse sémantique Analyse statistique Approximation par
recherche floue |
Non |
Non |
non |
|
Le traitement linguistique s'applique-t-il : A la reformulation
automatique de la requête Au filtrage des pages
trouvées Classement des
documents trouvés par ordre décroissant A la relance de la
recherche à partir d’un document ou d’une partie de document trouvé pour
affiner la pertinence |
Non Non Non non |
Non Non Non Non |
Non Non Non non |
Organisation :
Les documents trouvés sont organisés par un système de
catégorisation (avec plan de classement prédéfini et rangement). Il y a un
niveau maximum de niveaux hiérarchiques. Un système de classification
(autodétermination de l’organisation et rangement) est prévu début 2003 pour
les 3 produits.
Exploitation des résultats
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Intégration de modules spécifiques d’analyse des
corpus ?. Si oui : Représentation
graphique Cartographie Cartes sémantiques Représentations
multidimensionnelles Création automatique de
résumés Représentation en
réseau Autres : |
Oui Oui Oui Non Non Oui Oui Analyse de tendances |
Oui Oui non Non Non non Oui non |
Oui Oui non Non Non Oui Oui Analyse de tendances, |
Navigation
|
|
Produit
1 |
Produit
2 |
Produit
3 |
|
Hypertextuelle Entre représentation infographique et texte Entre représentation infographiques |
Non Oui non |
Non Non non |
Non Oui oui |
Domaine d’application :
Les domaines d’application du système mis en œuvre sont :
- la veille stratégique
- la mise à disposition de fond des connaissances (réservoir d’information)
- la diffusion, circulation des connaissances
- Autre : l’Intelligence économique
ANNEXE 10 :Graphes de connotation des
produits Datops

DOCUMENTS
ASSOCIES AU TEXTE DE CE RAPPORT


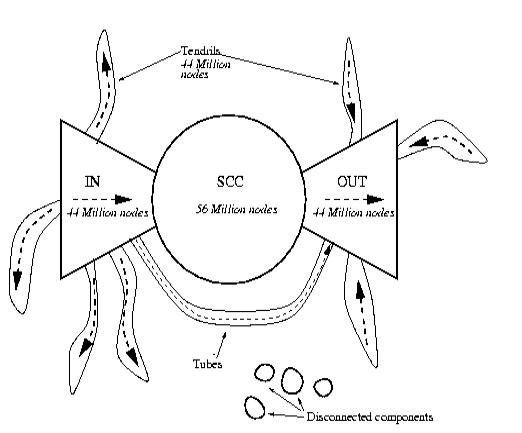
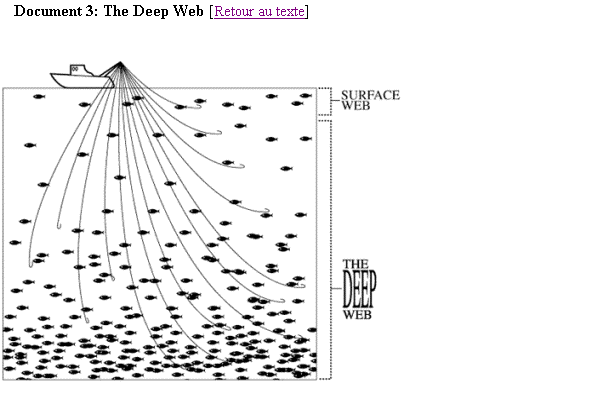

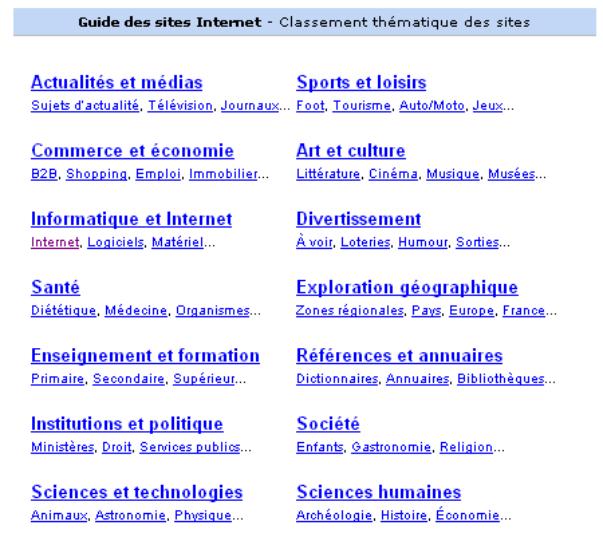
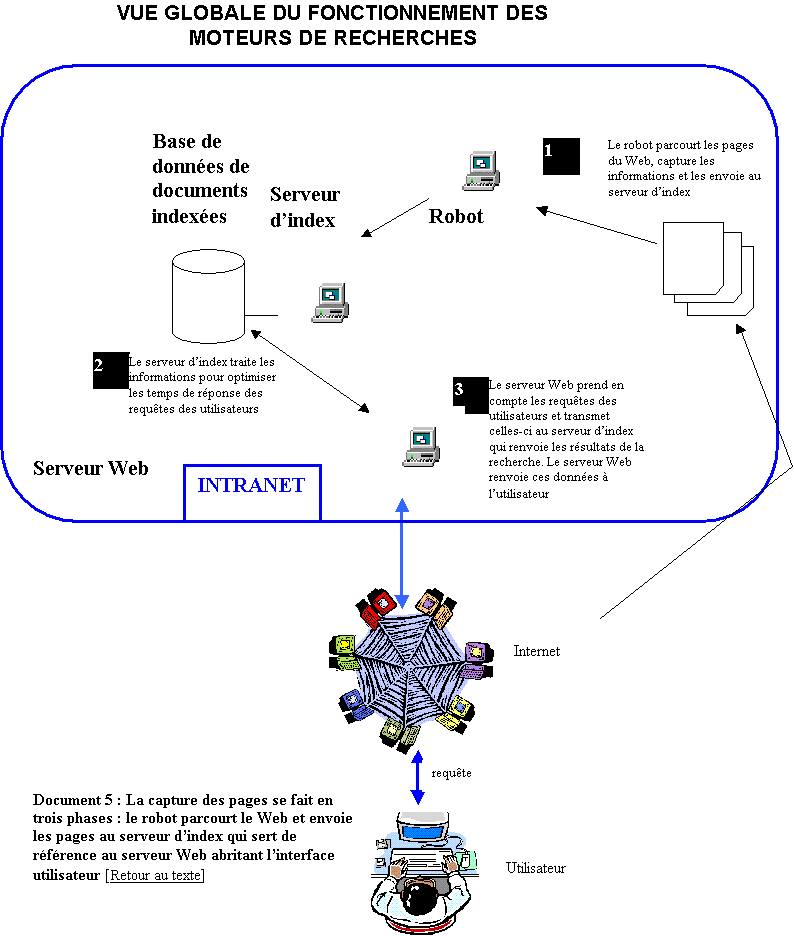
|
|
|
|
|
|
|
Moteur de recherche |
Date de
lancement |
Taille de
l’index (en pages) |
Délai de
rafraîchissement de l’index |
Nom du spider |
|
Altavista |
Décembre 95 |
1,1 milliards |
4 semaines |
Scooter |
|
Google |
98 |
2,5 milliards |
4 semaines |
Google bot |
|
HotBot |
Mai 96 |
2 milliards |
4 semaines |
Slurp |
|
Lycos |
Juin 95 |
2,5 milliards (index d’AlltheWeb) |
2 à 3 semaines |
Fast |
|
Fast/All The Webt |
Mai 99 |
2,5 milliards |
2 à 3 semaines |
Fast |
|
Altavista France |
15 février
2000 |
1,1 milliards
(toutes langues) 20 millions en
français |
4 à 6 semaines |
Scooter |
|
Voila |
Juillet 98 |
60 millions en
français |
1 à 2 semaines (variable) |
Echo |
|
HotBot France |
Aout 2001 |
2,5 milliards
(index de Fast) 12 millions en
français |
4 semaines |
Fast |
|
Lycos France |
Juin 1995 |
2,5 milliards
(index de Fast) 12 millions en
français |
2 à 3 semaines |
Fast |
Délai de rafraîchissement de l'index : délai moyen entre
deux renouvellements complets de l'index du moteur. Nom
du spider : nom du robot utilisé pour "aspirer" les pages
Web.
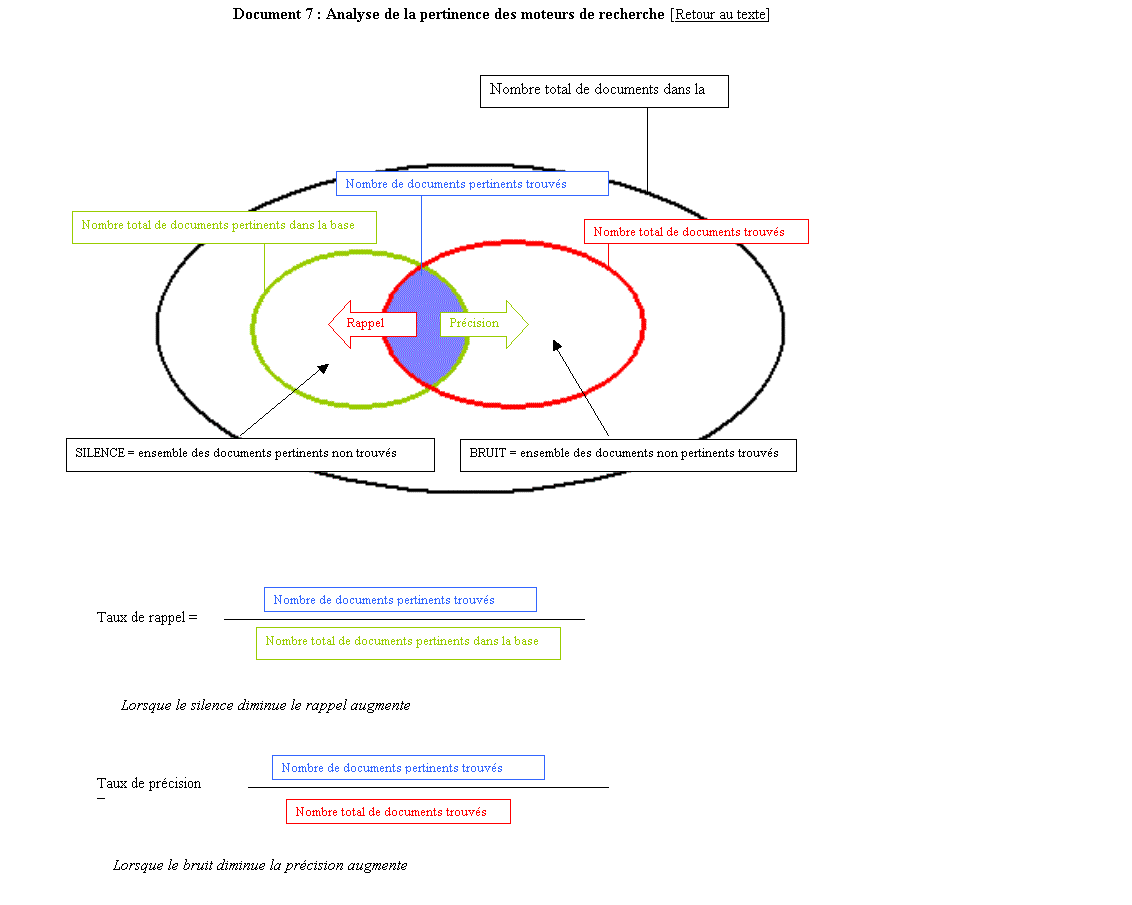

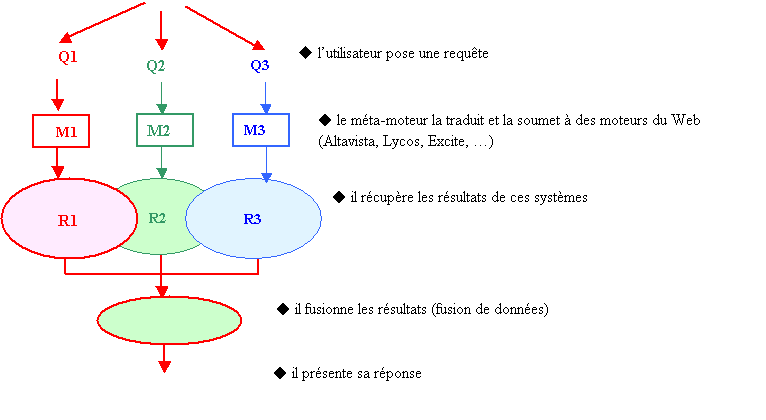
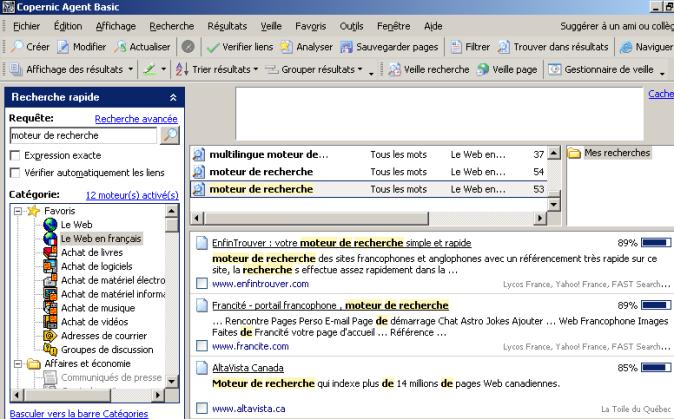
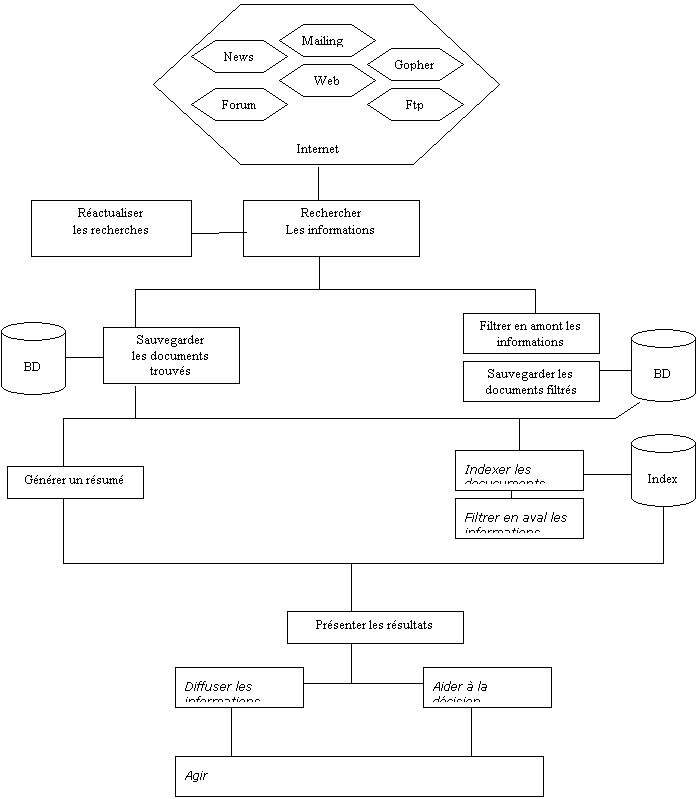
INDEX inversé des mots Page Poids Bienvenue : www.lesmoteursderecherche.com 2 Dossier : www.JDNet.fr 1 Guide : www.lesmoteursderecherche.com 1 Moteur : www.lesmoteursderecherche.com 3 www.JDNet.fr 1 Recherche : www.lesmoteursderecherche.com 3 www.JDNet.fr 1 Savoir : www.lesmoteursderecherche.com 2
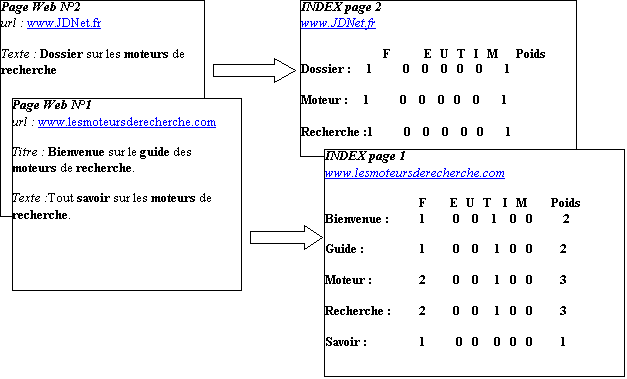

![]()
|
Niveaux d’indexation |
Altavista |
HOTBOT |
Voila |
Excite |
Lycos |
Infoseek |
Google |
|
Indexation du titre |
OUI |
OUI |
OUI |
OUI |
OUI |
OUI |
OUI |
|
URL de la page |
OUI |
OUI |
OUI |
|
|
OUI |
OUI |
|
Noms fichiers référencés dans la page (image,etc) |
OUI |
OUI |
|
|
|
OUI |
|
|
URL liens sortants |
OUI |
OUI |
OUI |
|
OUI |
OUI |
OUI |
|
Lemmatisation/troncature |
|
|
|
|
|
|
|
|
Majuscules/minuscules |
OUI |
OUI |
|
|
|
OUI |
OUI |
|
Accents |
OUI |
OUI |
|
|
OUI |
|
|
|
Distance des mots |
OUI |
OUI |
OUI |
|
OUI |
OUI |
OUI |
|
Anti-Dictionnaire (pour éliminer les mots vides) |
|
|
|
|
|
|
|
Terme générique du mot Fibres:

Fibres Terme
associé au mot Fibres:
Termes
spécifique du mot Fibres :
renvoie à
Coton
Jute
Laine
Lin
indexé par
Employés pour le mot Fibres:
![]() Fibres
chimiques
Fibres
chimiques

Article 1 :
http://www4.statcan.ca/francais/thesaurus/index_f.htm
31-203-XPB
Industries manufacturières du Canada, niveaux national et provincial 18 Jun 2002
Résumé:
clichage, climatisation, composition typographique, compresseurs, confiserie, construction, construction d'embarcations, construction navale, contenants, contreplaqués, cordages, coton, coutellerie, cuivre, céréales, drogues et médicaments, eau de vie, emploi, encres, engrais, enregistrements sonores, entreprises commerciales, exploitation minière, exploitations agricoles, expéditions des marchandises, farine, fenêtres, fer et acier, feutre, fibre de verre, fibres, fil métallique, films, filés, fonte, fonte et extrusion, fourrures, fruits, …
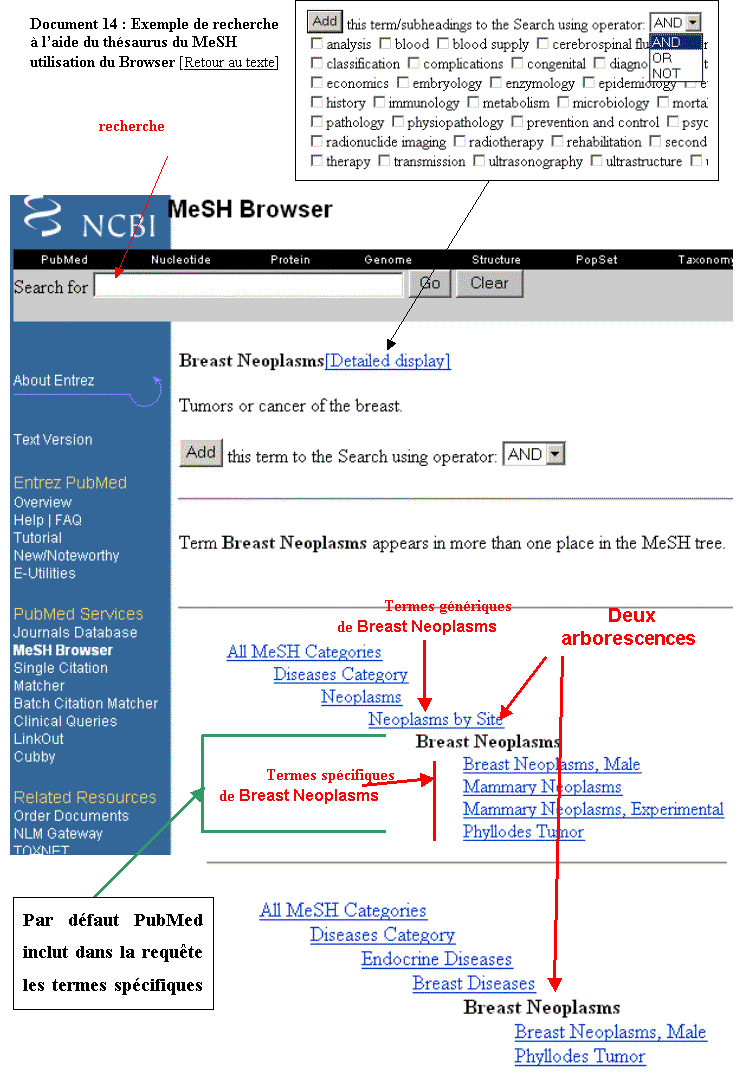
REQUETE UTILISATEUR : « produisent »
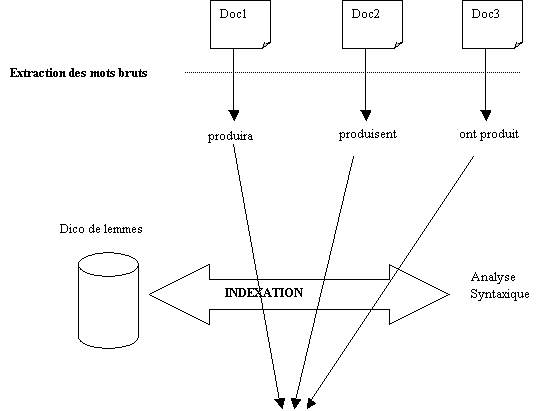
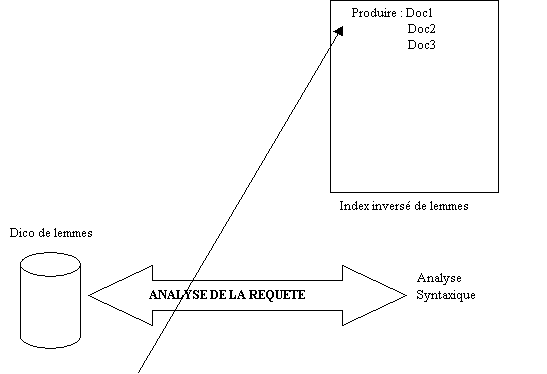
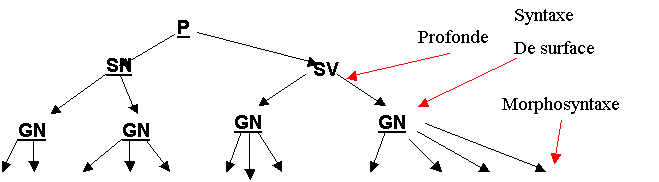
Adjectif nom art. Adjectif. Nom Verbe
Verbe adjectif
Nom Nom
Nom
possess. Indef. Numeral Adverbe Indéfini Prepos.
Mon
garçon de dix ans a
déjà lu plusieurs romans de Jules Verne.
P :
Phrase SN : syntagme nominal GNS : groupe nominal sujet GV : groupe verbal
SV :
syntagme verbal GNC :
groupe nominal complément
![]()
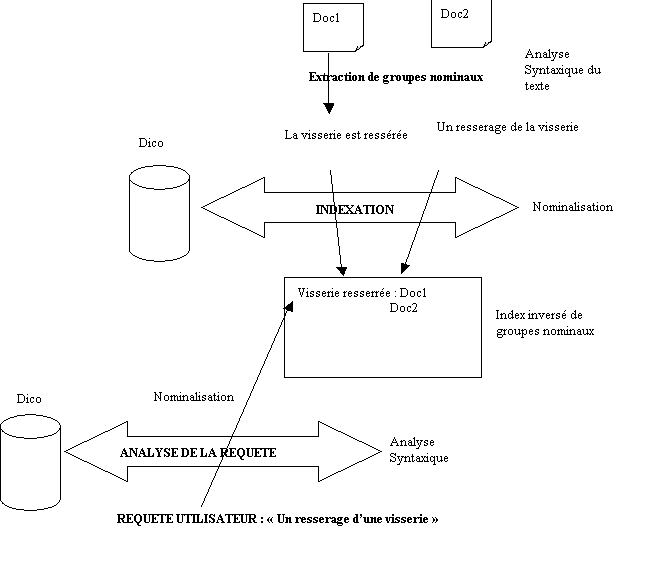
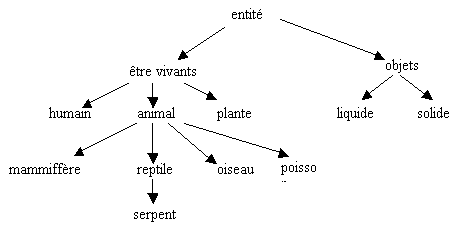
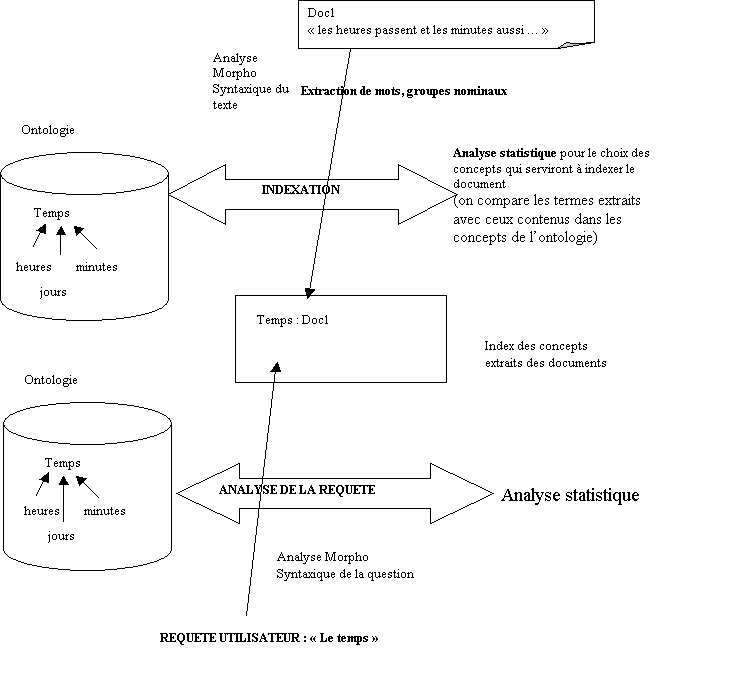
A l’indexation
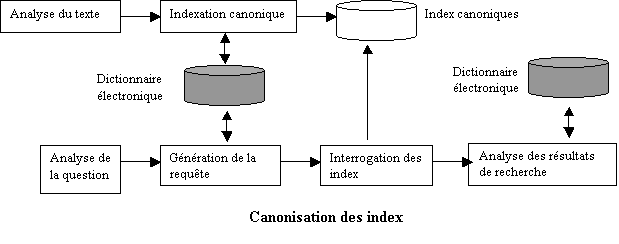
A l’interrogation
![]()
![]()
![]()


![]()

![]()
A l’indexation
Indexation texte intégral Définitions des concepts et des formes possibles des
termes Construction de la requête et interrogation
A l’interrogation
Utilisation du dictionnaire ou réseau sémantique externe au moteur
Document 22 : tableau présentant les opérateurs pouvant être utilisés sur
différents moteurs [Retour au texte]
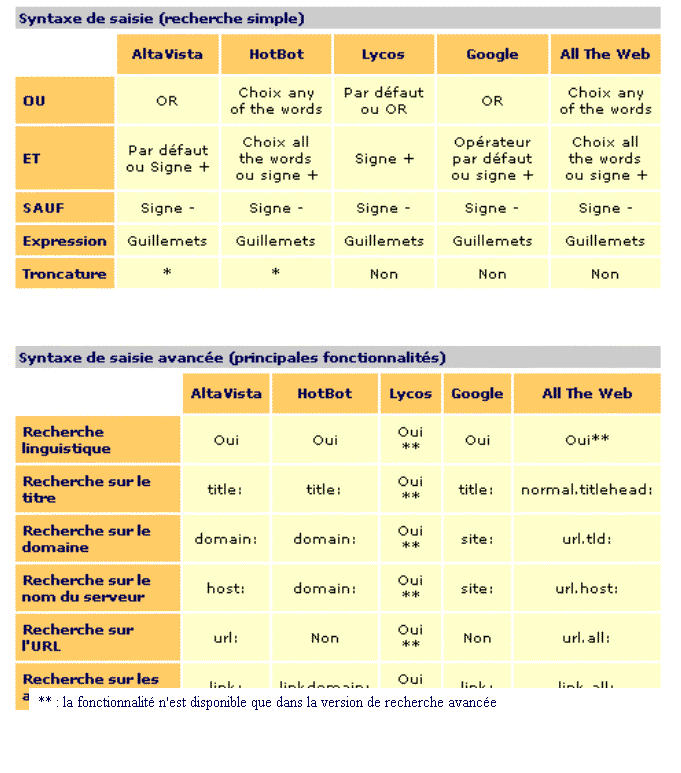
Collecte
avec préfiltrage autour d’une thématique générale A
Constitution
d’une base de connaissances autour de la requête B
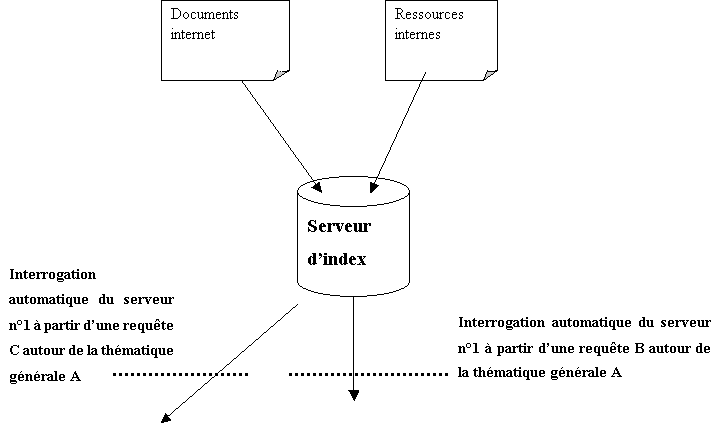


|
|
Exemple de recherche en langage naturel.
Affichons le premier document
de la liste de résultats ; les
mots associés aux concepts évoqués dans la recherche sont mis en valeur.
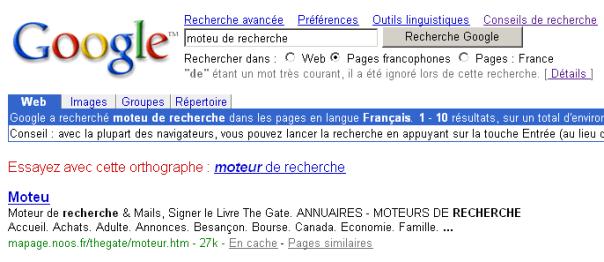
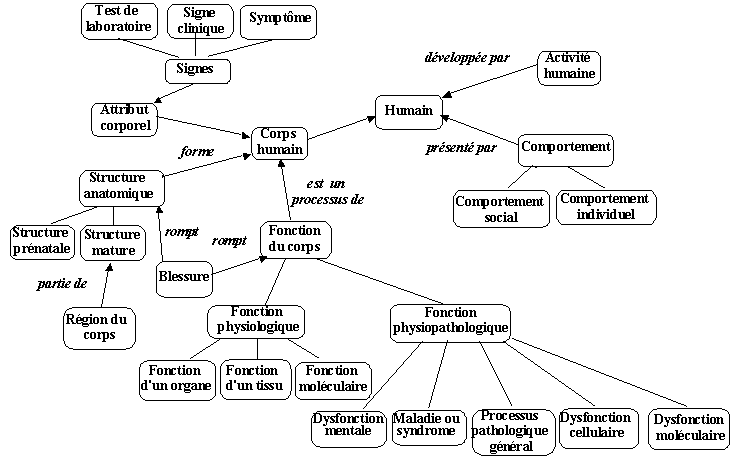

Document 30 : Exemple d'utilisation de Live Topics (qui
n’est plus disponible sur Altavista) [Retour au texte]
1- A la requête catalogage and indexation and internet and "live topics", le moteur de recherche AltaVista renvoie vers 345 852 réponses
2- Le nombre de réponses est bien trop important pour être exploitable. En cliquant sur le bouton REFINE qui se trouve à droite du formulaire de requête, le moteur va proposer la liste des termes qui ont été le plus souvent associés aux termes de la requête afin que l'utilisateur ajoute ou supprime certains de ces termes de l'équation de recherche.
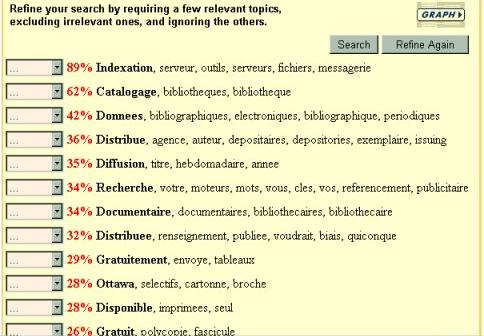
3-Si le navigateur utilisé
supporte java, une visualisation graphique des relations entre tous ces termes
est même proposée.